Json в python
Содержание:
- Complex JSON object decoding in Python
- Packaging
- And some basic terminology …
- Why JSON?
- Working with Simple Built-in Datatypes
- Testing
- Сохранение данных в JSON
- Object¶
- 19.2.1. Basic Usage¶
- Разбор JSON с использованием пользовательского класса
- Overview of JSON Serialization class JSONEncoder
- 기본 사용법¶
- Encoders and Decoders¶
- Serializing Custom Objects
- Основы
- Standard Compliance and Interoperability¶
- Стандартное соответствие и совместимость
Complex JSON object decoding in Python
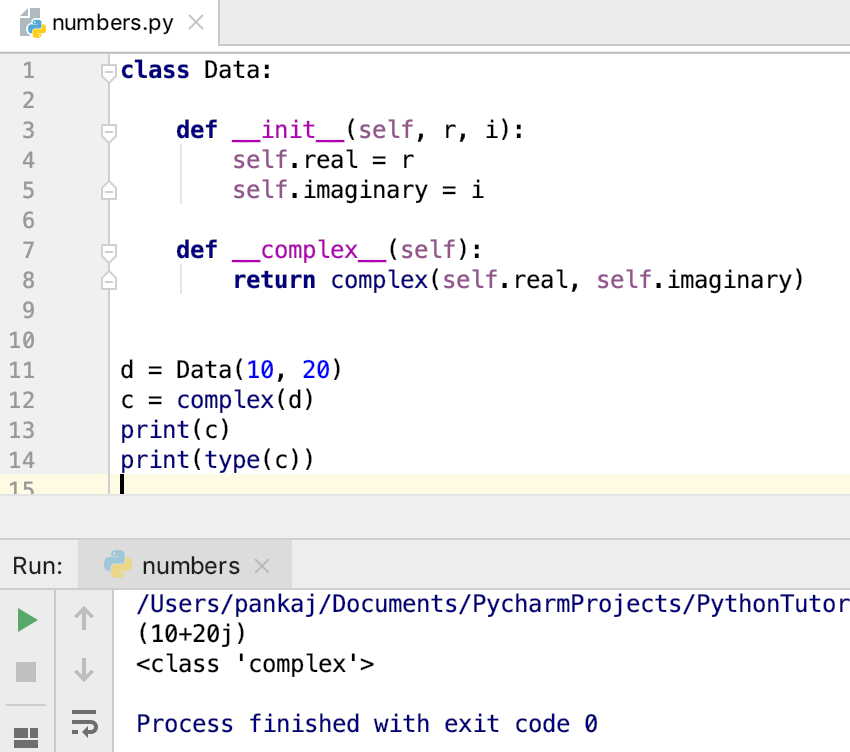
To decode complex object in JSON, use an object_hook parameter which checks JSON string contains the complex object or not. Example,
import json
# function check JSON string contains complex object
def is_complex(objct):
if '__complex__' in objct:
return complex(objct, objct)
return objct
# use of json loads method with object_hook for check object complex or not
complex_object =json.loads('{"__complex__": true, "real": 4, "img": 5}', object_hook = is_complex)
#here we not passed complex object so it's convert into dictionary
simple_object =json.loads('{"real": 6, "img": 7}', object_hook = is_complex)
print("Complex_object......",complex_object)
print("Without_complex_object......",simple_object)
Output:
Complex_object...... (4+5j)
Without_complex_object...... {'real': 6, 'img': 7}
Packaging
rustup default nightly pip wheel --no-binary=orjson orjson
This is an example of building a wheel using the repository as source,
installed from upstream, and a pinned version of Rust:
pip install maturin curl https://sh.rustup.rs -sSf | sh -s -- --default-toolchain nightly-2020-10-24 --profile minimal -y maturin build --no-sdist --release --strip --manylinux off ls -1 target/wheels
Problems with the Rust nightly channel may require pinning a version.
is known to be ok.
orjson is tested for amd64 and aarch64 on Linux, macOS, and Windows. It
may not work on 32-bit targets. It should be compiled with
on amd64 and on arm7. musl
libc is not supported, but building with
will probably work. The recommended flags are specified in
and will apply unless is set.
There are no runtime dependencies other than libc.
orjson’s tests are included in the source distribution on PyPI. It is
necessarily to install dependencies from PyPI specified in
. These require a C compiler. The tests do not
make network requests.
The tests should be run as part of the build. It can be run like this:
pip install -r test/requirements.txt pytest -q test
And some basic terminology …
- JSON exists as a string — a sequence (or series) of bytes. To convert a complex object (say a dictionary) in to a JSON representation, the object needs to be encoded as a “series of bytes”, for easy transmission or streaming — a process known as serialization.
- Deserialization is the reverse of serialization. It involves decoding data received in JSON format as native data types, that can be manipulated further.
Why JSON?
- Compared to its predecessor in server-client communication, XML, JSON is much smaller, translating into faster data transfers, and better experiences.
- JSON exists as a “sequence of bytes” which is very useful in the case we need to transmit (stream) data over a network.
- JSON is also extremely human-friendly since it is textual, and simultaneously machine-friendly.
- JSON has expressive syntax for representing arrays, objects, numbers and booleans.
Working with Simple Built-in Datatypes
Generally, the module encodes Python objects as JSON strings implemented by the class, and decodes JSON strings into Python objects using the class.
Testing
The library has comprehensive tests. There are tests against fixtures in the
JSONTestSuite and
nativejson-benchmark
repositories. It is tested to not crash against the
Big List of Naughty Strings.
It is tested to not leak memory. It is tested to not crash
against and not accept invalid UTF-8. There are integration tests
exercising the library’s use in web servers (gunicorn using multiprocess/forked
workers) and when
multithreaded. It also uses some tests from the ultrajson library.
orjson is the most correct of the compared libraries. This graph shows how each
library handles a combined 342 JSON fixtures from the
JSONTestSuite and
nativejson-benchmark tests:
| Library | Invalid JSON documents not rejected | Valid JSON documents not deserialized |
|---|---|---|
| orjson | ||
| ujson | 38 | |
| rapidjson | 6 | |
| simplejson | 13 | |
| json | 17 |
This shows that all libraries deserialize valid JSON but only orjson
correctly rejects the given invalid JSON fixtures. Errors are largely due to
accepting invalid strings and numbers.
The graph above can be reproduced using the script.
Сохранение данных в JSON
Чтобы записать информацию в формате JSON с помощью средств языка Python, нужно прежде всего подключить модуль json, воспользовавшись командой import json в начале файла с кодом программы. Метод dumps отвечает за автоматическую упаковку данных в JSON, принимая при этом переменную, которая содержит всю необходимую информацию. В следующем примере демонстрируется кодирование словаря под названием dictData. В нем имеются некие сведения о пользователе интернет-портала, такие как идентификационный код, логин, пароль, полное имя, номер телефона, адрес электронной почты и данные об активности. Эти значения представлены в виде обычных строк, а также целых чисел и булевых литералов True/False.
import json
dictData = { "ID" : 210450,
"login" : "admin",
"name" : "John Smith",
"password" : "root",
"phone" : 5550505,
"email" : "smith@mail.com",
"online" : True }
jsonData = json.dumps(dictData)
print(jsonData)
{"ID": 210450, "login": "admin", "name": "John Smith", "password": "root", "phone": 5550505, "email": "smith@mail.com", "online": true}
Результат выполнения метода dumps передается в переменную под названием jsonData. Таким образом, словарь dictData был преобразован в JSON-формат всего одной строчкой. Как можно увидеть, благодаря функции print, все сведения были закодированы в своем изначальном виде. Стоит заметить, что данные из поля online были преобразованы из литерала True в true.
С помощью Python сделаем запись json в файл. Для этого дополним код предыдущего примера следующим образом:
with open("data.json", "w") as file:
file.write(jsonData)
Подробнее про запись данных в текстовые файлы описано в отдельной статье на нашем сайте.
Object¶
A JSON object is a dictionary of key-value pairs, where the key is a
Unicode string and the value is any JSON value.
- *json_object(void)
-
Return value: New reference.
Returns a new JSON object, or NULL on error. Initially, the
object is empty.
- size_t json_object_size(const *object)
-
Returns the number of elements in object, or 0 if object is not
a JSON object.
- *json_object_get(const *object, const char *key)
-
Return value: Borrowed reference.
Get a value corresponding to key from object. Returns NULL if
key is not found and on error.
- int json_object_set( *object, const char *key, *value)
-
Set the value of key to value in object. key must be a
valid null terminated UTF-8 encoded Unicode string. If there
already is a value for key, it is replaced by the new value.
Returns 0 on success and -1 on error.
- int json_object_set_nocheck( *object, const char *key, *value)
-
Like , but doesn’t check that key is
valid UTF-8. Use this function only if you are certain that this
really is the case (e.g. you have already checked it by other
means).
- int json_object_set_new( *object, const char *key, *value)
-
Like but steals the reference to
value. This is useful when value is newly created and not used
after the call.
- int json_object_set_new_nocheck( *object, const char *key, *value)
-
Like , but doesn’t check that key is
valid UTF-8. Use this function only if you are certain that this
really is the case (e.g. you have already checked it by other
means).
- int json_object_del( *object, const char *key)
-
Delete key from object if it exists. Returns 0 on success, or
-1 if key was not found. The reference count of the removed value
is decremented.
- int json_object_clear( *object)
-
Remove all elements from object. Returns 0 on success and -1 if
object is not a JSON object. The reference count of all removed
values are decremented.
- int json_object_update( *object, *other)
-
Update object with the key-value pairs from other, overwriting
existing keys. Returns 0 on success or -1 on error.
The following functions implement an iteration protocol for objects,
allowing to iterate through all key-value pairs in an object. The
items are not returned in any particular order, as this would require
sorting due to the internal hashtable implementation.
- void *json_object_iter( *object)
-
Returns an opaque iterator which can be used to iterate over all
key-value pairs in object, or NULL if object is empty.
- void *json_object_iter_at( *object, const char *key)
-
Like , but returns an iterator to the
key-value pair in object whose key is equal to key, or NULL if
key is not found in object. Iterating forward to the end of
object only yields all key-value pairs of the object if key
happens to be the first key in the underlying hash table.
- void *json_object_iter_next( *object, void *iter)
-
Returns an iterator pointing to the next key-value pair in object
after iter, or NULL if the whole object has been iterated
through.
- const char *json_object_iter_key(void *iter)
-
Extract the associated key from iter.
- *json_object_iter_value(void *iter)
-
Return value: Borrowed reference.
Extract the associated value from iter.
- int json_object_iter_set( *object, void *iter, *value)
-
Set the value of the key-value pair in object, that is pointed to
by iter, to value.
- int json_object_iter_set_new( *object, void *iter, *value)
-
Like , but steals the reference to
value. This is useful when value is newly created and not used
after the call.
The iteration protocol can be used for example as follows:
19.2.1. Basic Usage¶
- (obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
-
Serialize obj as a JSON formatted stream to fp (a -supporting
) using this .If skipkeys is true (default: ), then dict keys that are not
of a basic type (, , , ,
) will be skipped instead of raising a .The module always produces objects, not
objects. Therefore, must support
input.If ensure_ascii is true (the default), the output is guaranteed to
have all incoming non-ASCII characters escaped. If ensure_ascii is
false, these characters will be output as-is.If check_circular is false (default: ), then the circular
reference check for container types will be skipped and a circular reference
will result in an (or worse).If allow_nan is false (default: ), then it will be a
to serialize out of range values (,
, ) in strict compliance of the JSON specification.
If allow_nan is true, their JavaScript equivalents (,
, ) will be used.If indent is a non-negative integer or string, then JSON array elements and
object members will be pretty-printed with that indent level. An indent level
of 0, negative, or will only insert newlines. (the default)
selects the most compact representation. Using a positive integer indent
indents that many spaces per level. If indent is a string (such as ),
that string is used to indent each level.Changed in version 3.2: Allow strings for indent in addition to integers.
If specified, separators should be an
tuple. The default is if indent is and
otherwise. To get the most compact JSON representation,
you should specify to eliminate whitespace.Changed in version 3.4: Use as default if indent is not .
If specified, default should be a function that gets called for objects that
can’t otherwise be serialized. It should return a JSON encodable version of
the object or raise a . If not specified,
is raised.If sort_keys is true (default: ), then the output of
dictionaries will be sorted by key.To use a custom subclass (e.g. one that overrides the
method to serialize additional types), specify it with the
cls kwarg; otherwise is used.
- (obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
-
Serialize obj to a JSON formatted using this . The arguments have the same meaning as in
.Note
Unlike and , JSON is not a framed protocol,
so trying to serialize multiple objects with repeated calls to
using the same fp will result in an invalid JSON file.Note
Keys in key/value pairs of JSON are always of the type . When
a dictionary is converted into JSON, all the keys of the dictionary are
coerced to strings. As a result of this, if a dictionary is converted
into JSON and then back into a dictionary, the dictionary may not equal
the original one. That is, if x has non-string
keys.
- (fp, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
-
Deserialize fp (a -supporting
containing a JSON document) to a Python object using this .object_hook is an optional function that will be called with the result of
any object literal decoded (a ). The return value of
object_hook will be used instead of the . This feature can be used
to implement custom decoders (e.g. JSON-RPC
class hinting).object_pairs_hook is an optional function that will be called with the
result of any object literal decoded with an ordered list of pairs. The
return value of object_pairs_hook will be used instead of the
. This feature can be used to implement custom decoders that
rely on the order that the key and value pairs are decoded (for example,
will remember the order of insertion). If
object_hook is also defined, the object_pairs_hook takes priority.Changed in version 3.1: Added support for object_pairs_hook.
parse_float, if specified, will be called with the string of every JSON
float to be decoded. By default, this is equivalent to .
This can be used to use another datatype or parser for JSON floats
(e.g. ).parse_int, if specified, will be called with the string of every JSON int
to be decoded. By default, this is equivalent to . This can
be used to use another datatype or parser for JSON integers
(e.g. ).parse_constant, if specified, will be called with one of the following
strings: , , .
This can be used to raise an exception if invalid JSON numbers
are encountered.Changed in version 3.1: parse_constant doesn’t get called on ‘null’, ‘true’, ‘false’ anymore.
To use a custom subclass, specify it with the
kwarg; otherwise is used. Additional keyword arguments
will be passed to the constructor of the class.If the data being deserialized is not a valid JSON document, a
will be raised.
Разбор JSON с использованием пользовательского класса
По умолчанию объект JSON анализируется в питоне ДИКТ. Иногда вам может понадобиться автоматически создать объект вашего собственного класса из данных JSON. Вы можете сделать это, указав object_hook функция, которая обрабатывает преобразование. В следующем примере показано, как.
Вот пользовательский класс, представляющий Человек.
Экземпляр этого класса создается путем передачи необходимых аргументов следующим образом:
Чтобы использовать этот класс для создания экземпляров при разборе JSON, вам нужен object_hook функция определяется следующим образом: функция получает питона ДИКТ и возвращает объект правильного класса.
Теперь вы можете использовать это object_hook функция при вызове анализатора JSON.
Overview of JSON Serialization class JSONEncoder
JSONEncoder class is used for serialization of any Python object while performing encoding. It contains three different methods of encoding which are
- default(o) – Implemented in the subclass and return serialize object for o object.
- encode(o) – Same as json.dumps() method return JSON string of Python data structure.
- iterencode(o) – Represent string one by one and encode object o.
With the help of encode() method of JSONEncoder class, we can also encode any Python object.
# import JSONEncoder class from json
from json.encoder import JSONEncoder
colour_dict = { "colour": }
# directly called encode method of JSON
JSONEncoder().encode(colour_dict)
Output:
'{"colour": }'
기본 사용법¶
- (obj, fp, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
-
이 를 사용하여 obj를 JSON 형식 스트림으로 fp(를 지원하는 )로 직렬화합니다.
skipkeys가 참이면 (기본값: ), 기본형(, , , , )이 아닌 딕셔너리 키는 를 발생시키는 대신 건너뜁니다.
모듈은 항상 객체가 아니라 객체를 생성합니다. 따라서, 는 입력을 지원해야 합니다.
ensure_ascii가 참(기본값)이면, 출력에서 모든 비 ASCII 문자가 이스케이프 되도록 보장됩니다. ensure_ascii가 거짓이면, 그 문자들은 있는 그대로 출력됩니다.
check_circular가 거짓이면 (기본값: ), 컨테이너형에 대한 순환 참조 검사를 건너뛰고 순환 참조는 를 일으킵니다 (또는 더 나빠질 수 있습니다).
allow_nan이 거짓이면 (기본값: ), JSON 사양을 엄격히 준수하여 범위를 벗어난 값(, , )을 직렬화하면 를 일으킵니다. allow_nan이 참이면, JavaScript의 대응 물(, , )이 사용됩니다.
indent가 음이 아닌 정수나 문자열이면, JSON 배열 요소와 오브젝트 멤버가 해당 들여쓰기 수준으로 예쁘게 인쇄됩니다. 0, 음수 또는 의 들여쓰기 수준은 줄 넘김만 삽입합니다. (기본값)은 가장 간결한(compact) 표현을 선택합니다. 양의 정수 indent를 사용하면, 수준 당 그만큼의 스페이스로 들여쓰기합니다. indent가 문자열이면 (가령 ), 각 수준을 들려 쓰는 데 그 문자열을 사용합니다.
버전 3.2에서 변경: indent에 정수뿐만 아니라 문자열을 허용합니다.
지정되면, separators는 튜플이어야 합니다. 기본값은 indent가 이면 이고, 그렇지 않으면 입니다. 가장 간결한 JSON 표현을 얻으려면, 를 지정하여 공백을 제거해야 합니다.
버전 3.4에서 변경: indent가 이 아니면, 를 기본값으로 사용합니다.
지정되면, default는 달리 직렬화할 수 없는 객체에 대해 호출되는 함수여야 합니다. 객체의 JSON 인코딩 가능한 버전을 반환하거나 를 발생시켜야 합니다. 지정하지 않으면, 가 발생합니다.
sort_keys가 참이면 (기본값: ), 딕셔너리의 출력이 키로 정렬됩니다.
사용자 정의 서브 클래스(예를 들어, 메서드를 재정의하여 추가 형을 직렬화하는 것)를 사용하려면, cls 키워드 인자로 지정하십시오; 그렇지 않으면 가 사용됩니다.
버전 3.6에서 변경: 모든 선택적 매개 변수는 이제 입니다.
참고
과 과 달리, JSON은 프레임 프로토콜이 아니므로 같은 fp를 사용하여 를 반복 호출하여 여러 객체를 직렬화하려고 하면 잘못된 JSON 파일이 생성됩니다.
- (obj, *, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
-
이 를 사용하여 obj를 JSON 형식의 로 직렬화합니다. 인자는 에서와 같은 의미입니다.
참고
JSON의 키/값 쌍에 있는 키는 항상 형입니다. 딕셔너리를 JSON으로 변환하면, 딕셔너리의 모든 키가 문자열로 강제 변환됩니다. 이것의 결과로, 딕셔너리를 JSON으로 변환한 다음 다시 딕셔너리로 변환하면, 딕셔너리가 원래의 것과 같지 않을 수 있습니다. 즉, x에 비 문자열 키가 있으면 입니다.
- (fp, *, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
-
이 를 사용하여 fp(JSON 문서를 포함하는 를 지원하는 이나 )를 파이썬 객체로 역 직렬화합니다.
object_hook은 모든 오브젝트 리터럴의 디코딩된 결과()로 호출되는 선택적 함수입니다. object_hook의 반환 값이 대신에 사용됩니다. 이 기능은 사용자 정의 디코더를 구현하는 데 사용할 수 있습니다 (예를 들어, JSON-RPC 클래스 힌팅(class hinting)).
object_pairs_hook은 모든 오브젝트 리터럴의 쌍의 순서 있는 목록으로 디코딩된 결과로 호출되는 선택적 함수입니다. 대신 object_pairs_hook의 반환 값이 사용됩니다. 이 기능은 사용자 정의 디코더를 구현하는 데 사용할 수 있습니다. object_hook도 정의되어 있으면, object_pairs_hook이 우선순위를 갖습니다.
버전 3.1에서 변경: object_pairs_hook에 대한 지원이 추가되었습니다.
parse_float가 지정되면, 디코딩될 모든 JSON float의 문자열로 호출됩니다. 기본적으로, 이것은 와 동등합니다. JSON float에 대해 다른 데이터형이나 구문 분석기를 사용하고자 할 때 사용될 수 있습니다 (예를 들어, ).
parse_int가 지정되면, 디코딩될 모든 JSON int의 문자열로 호출됩니다. 기본적으로 이것은 와 동등합니다. JSON 정수에 대해 다른 데이터형이나 구문 분석기를 사용하고자 할 때 사용될 수 있습니다 (예를 들어 ).
parse_constant가 지정되면, 다음과 같은 문자열 중 하나로 호출됩니다: , , . 잘못된 JSON 숫자를 만날 때 예외를 발생시키는 데 사용할 수 있습니다.
버전 3.1에서 변경: parse_constant는 더는 〈null〉, 〈true〉, 〈false’에 대해 호출되지 않습니다.
사용자 정의 서브 클래스를 사용하려면, 키워드 인자로 지정하십시오; 그렇지 않으면 가 사용됩니다. 추가 키워드 인자는 클래스 생성자에 전달됩니다.
역 직렬화되는 데이터가 유효한 JSON 문서가 아니면, 가 발생합니다.
버전 3.6에서 변경: 모든 선택적 매개 변수는 이제 입니다.
버전 3.6에서 변경: fp는 이제 이 될 수 있습니다. 입력 인코딩은 UTF-8, UTF-16 또는 UTF-32 여야 합니다.
Encoders and Decoders¶
- class (*, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, strict=True, object_pairs_hook=None)
-
Simple JSON decoder.
Performs the following translations in decoding by default:
JSON
Python
object
dict
array
list
string
str
number (int)
int
number (real)
float
true
True
false
False
null
None
It also understands , , and as their
corresponding values, which is outside the JSON spec.object_hook, if specified, will be called with the result of every JSON
object decoded and its return value will be used in place of the given
. This can be used to provide custom deserializations (e.g. to
support JSON-RPC class hinting).object_pairs_hook, if specified will be called with the result of every
JSON object decoded with an ordered list of pairs. The return value of
object_pairs_hook will be used instead of the . This
feature can be used to implement custom decoders. If object_hook is also
defined, the object_pairs_hook takes priority.Changed in version 3.1: Added support for object_pairs_hook.
parse_float, if specified, will be called with the string of every JSON
float to be decoded. By default, this is equivalent to .
This can be used to use another datatype or parser for JSON floats
(e.g. ).parse_int, if specified, will be called with the string of every JSON int
to be decoded. By default, this is equivalent to . This can
be used to use another datatype or parser for JSON integers
(e.g. ).parse_constant, if specified, will be called with one of the following
strings: , , .
This can be used to raise an exception if invalid JSON numbers
are encountered.If strict is false ( is the default), then control characters
will be allowed inside strings. Control characters in this context are
those with character codes in the 0–31 range, including (tab),
, and .If the data being deserialized is not a valid JSON document, a
will be raised.Changed in version 3.6: All parameters are now .
- (s)
-
Return the Python representation of s (a instance
containing a JSON document).will be raised if the given JSON document is not
valid.
- (s)
-
Decode a JSON document from s (a beginning with a
JSON document) and return a 2-tuple of the Python representation
and the index in s where the document ended.This can be used to decode a JSON document from a string that may have
extraneous data at the end.
Serializing Custom Objects
In this section, we are going to define a custom class, proceed to create an instance and attempt to serialize this instance, as we did with the built in types.
User class definition
>>> from json_user import User>>> new_user = User( name = "Foo Bar", age = 78, friends = , balance = 345.80, other_names = ("Doe","Joe"), active = True, spouse = None)>>> json.dumps(new_user)
And the output:
TypeError: Object of type 'User' is not JSON serializable
I bet this comes as no surprise to us, since earlier on we established that the module only understands the built-in types, and is not one of those.
We need to send our user data to a client over anetwork, so how do we get ourselves out of this error state?
A simple solution would be to convert our custom type in to a serializable type — i.e a built-in type. We can conveniently define a method that returns a dictionary representation of our object. takes in a optional argument, , which specifies a function to be called if the object is not serializable. This function returns a JSON encodable version of the object.
Function to convert an obj to its dict representation
Lets go through what does:
- The function takes in an object as the only argument.
- We then create a dictionary named to act as the representation of our object.
- By calling the special dunder methods and on the object we are able to get crucial metadata on the object i.e the class name and the module name — with which we shall reconstruct the object when decoding.
- Having added the metadata to we finally add the instance attributes by accessing . (Python stores instance attributes in a dictionary under the hood)
- The resulting is now serializable.
At this point we can comfortably call on the object and pass in .
>>> from json_convert_to_dict import convert_to_dict>>> data = json.dumps(new_user,default=convert_to_dict,indent=4, sort_keys=True)>>> print(data)
Hooray! And we get ourselves a nice little JSON object.
{ "__class__": "User", "__module__": "__main__", "active": true, "age": 78, "balance": 345.8, "friends": , "name": "Foo Bar", "other_names": , "spouse": null}
Основы
json.dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw) — сериализует obj как форматированный JSON поток в fp.
Если skipkeys = True, то ключи словаря не базового типа (str, unicode, int, long, float, bool, None) будут проигнорированы, вместо того, чтобы вызывать исключение TypeError.
Если ensure_ascii = True, все не-ASCII символы в выводе будут экранированы последовательностями \uXXXX, и результатом будет строка, содержащая только ASCII символы. Если ensure_ascii = False, строки запишутся как есть.
Если check_circular = False, то проверка циклических ссылок будет пропущена, а такие ссылки будут вызывать OverflowError.
Если allow_nan = False, при попытке сериализовать значение с запятой, выходящее за допустимые пределы, будет вызываться ValueError (nan, inf, -inf) в строгом соответствии со спецификацией JSON, вместо того, чтобы использовать эквиваленты из JavaScript (NaN, Infinity, -Infinity).
Если indent является неотрицательным числом, то массивы и объекты в JSON будут выводиться с этим уровнем отступа. Если уровень отступа 0, отрицательный или «», то вместо этого будут просто использоваться новые строки. Значение по умолчанию None отражает наиболее компактное представление. Если indent — строка, то она и будет использоваться в качестве отступа.
Если sort_keys = True, то ключи выводимого словаря будут отсортированы.
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw) — сериализует obj в строку JSON-формата.
Аргументы имеют то же значение, что и для dump().
Ключи в парах ключ/значение в JSON всегда являются строками. Когда словарь конвертируется в JSON, все ключи словаря преобразовываются в строки. В результате этого, если словарь сначала преобразовать в JSON, а потом обратно в словарь, то можно не получить словарь, идентичный исходному. Другими словами, loads(dumps(x)) != x, если x имеет нестроковые ключи.
json.load(fp, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw) — десериализует JSON из fp.
object_hook — опциональная функция, которая применяется к результату декодирования объекта (dict). Использоваться будет значение, возвращаемое этой функцией, а не полученный словарь.
object_pairs_hook — опциональная функция, которая применяется к результату декодирования объекта с определённой последовательностью пар ключ/значение. Будет использован результат, возвращаемый функцией, вместо исходного словаря. Если задан так же object_hook, то приоритет отдаётся object_pairs_hook.
parse_float, если определён, будет вызван для каждого значения JSON с плавающей точкой. По умолчанию, это эквивалентно float(num_str).
parse_int, если определён, будет вызван для строки JSON с числовым значением. По умолчанию эквивалентно int(num_str).
parse_constant, если определён, будет вызван для следующих строк: «-Infinity», «Infinity», «NaN». Может быть использовано для возбуждения исключений при обнаружении ошибочных чисел JSON.
Если не удастся десериализовать JSON, будет возбуждено исключение ValueError.
json.loads(s, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw) — десериализует s (экземпляр str, содержащий документ JSON) в объект Python.
Standard Compliance and Interoperability¶
The JSON format is specified by RFC 7159 and by
ECMA-404.
This section details this module’s level of compliance with the RFC.
For simplicity, and subclasses, and
parameters other than those explicitly mentioned, are not considered.
This module does not comply with the RFC in a strict fashion, implementing some
extensions that are valid JavaScript but not valid JSON. In particular:
-
Infinite and NaN number values are accepted and output;
-
Repeated names within an object are accepted, and only the value of the last
name-value pair is used.
Since the RFC permits RFC-compliant parsers to accept input texts that are not
RFC-compliant, this module’s deserializer is technically RFC-compliant under
default settings.
Character Encodings
The RFC requires that JSON be represented using either UTF-8, UTF-16, or
UTF-32, with UTF-8 being the recommended default for maximum interoperability.
As permitted, though not required, by the RFC, this module’s serializer sets
ensure_ascii=True by default, thus escaping the output so that the resulting
strings only contain ASCII characters.
Other than the ensure_ascii parameter, this module is defined strictly in
terms of conversion between Python objects and
, and thus does not otherwise directly address
the issue of character encodings.
The RFC prohibits adding a byte order mark (BOM) to the start of a JSON text,
and this module’s serializer does not add a BOM to its output.
The RFC permits, but does not require, JSON deserializers to ignore an initial
BOM in their input. This module’s deserializer raises a
when an initial BOM is present.
The RFC does not explicitly forbid JSON strings which contain byte sequences
that don’t correspond to valid Unicode characters (e.g. unpaired UTF-16
surrogates), but it does note that they may cause interoperability problems.
By default, this module accepts and outputs (when present in the original
) code points for such sequences.
Infinite and NaN Number Values
The RFC does not permit the representation of infinite or NaN number values.
Despite that, by default, this module accepts and outputs ,
, and as if they were valid JSON number literal values:
>>> # Neither of these calls raises an exception, but the results are not valid JSON
>>> json.dumps(float('-inf'))
'-Infinity'
>>> json.dumps(float('nan'))
'NaN'
>>> # Same when deserializing
>>> json.loads('-Infinity')
-inf
>>> json.loads('NaN')
nan
In the serializer, the allow_nan parameter can be used to alter this
behavior. In the deserializer, the parse_constant parameter can be used to
alter this behavior.
Repeated Names Within an Object
The RFC specifies that the names within a JSON object should be unique, but
does not mandate how repeated names in JSON objects should be handled. By
default, this module does not raise an exception; instead, it ignores all but
the last name-value pair for a given name:
>>> weird_json = '{"x": 1, "x": 2, "x": 3}'
>>> json.loads(weird_json)
{'x': 3}
The object_pairs_hook parameter can be used to alter this behavior.
Top-level Non-Object, Non-Array Values
The old version of JSON specified by the obsolete RFC 4627 required that
the top-level value of a JSON text must be either a JSON object or array
(Python or ), and could not be a JSON null,
boolean, number, or string value. RFC 7159 removed that restriction, and
this module does not and has never implemented that restriction in either its
serializer or its deserializer.
Regardless, for maximum interoperability, you may wish to voluntarily adhere
to the restriction yourself.
Стандартное соответствие и совместимость
Формат JSON указан в RFC 7159 и ECMA-404. В этом разделе описывается уровень соответствия этого модуля с RFC
Для упрощения, подклассы и , и параметры, которые отличаются от указанных, не берутся во внимание
Этот модуль не соответствует RFC, устанавливая некоторые расширения, которые являются рабочими для JavaScript, но недействительными для JSON. В частности:
- и принимаются и выводятся;
- Повторяемые имена внутри объекта принимаются и выводятся, но только последнее значение дублируемого ключа.
Поскольку RFC разрешает синтаксическим анализаторам, совместимым с RFC, принимать входные тексты, которые не соответствуют требованиям RFC, десериализатор этого модуля технически соответствует стандартным настройкам RFC.
Кодировка символов
RFC требует, чтобы JSON был представлен с использованием UTF-8, UTF-16 или UTF-32, при том, что UTF-8 является рекомендуемым по умолчанию для максимальной совместимости.
Возможно, но не обязательно для RFC, сериализаторы этого модуля устанавливают по умолчанию, таким образом строки содержат только символы ASCII.
Кроме параметра , этот модуль напрямую не затрагивает проблему кодировки символов.
RFC запрещает маркер последовательности байтов (BOM) в начало текста JSON и сериализатор этого модуля не добавляет BOM. RFC позволет, не не требует десериализаторы JSON игнорировать BOM на входе. Десериализатор этого модуля вызывает при наличии BOM.
RFC явно не запрещает строки JSON, содержащие последовательность байт, которая не соответствует валидным символам Unicode (например, непарные UTF-16 заменители), он отмечает — они могут вызывать проблемы совместимости. По умолчанию этот модуль принимает и выводит (если есть в исходной строке) специальные последовательности кода.
Infinite и NaN
RFC не допускает представления для значений или . Несмотря на это, по умолчанию этот модуль принимает и выводит , , и , как если бы они были действительно буквальными значениями числа в JSON:
В сериализаторе параметр используется для изменения этого поведения. В десериализаторе параметр этот переметр — .
Повторяющиеся имена внутри объекта
RFC указывает, что имена в объекте JSON должны быть уникальными, но не указывает, как должны обрабатываться повторяющиеся имена в объектах JSON. По умолчанию этот модуль не вызывает исключения; вместо этого он игнорирует все, кроме последней пары ключ/значение для данного ключа:
Параметр может использоваться для изменения этого.
Значение верхнего уровня Non-Object, Non-Array
Старая версия JSON указанная устаревшим RFC 4627 требовала, чтобы значение верхнего уровня текста JSON было объектом JSON или массивом (Python или ), или не было . RFC 7159 убрало это ограничение, поэтому этот модуль не выполнял и никогда не применял это ограничение ни в своем сериализаторе, ни в десериализаторе.
Тем не менее, для максимальной совместимости, вы можете добровольно придерживаться этого ограничения.
Ограничения реализации
Некоторые реализации десериализатора JSON имеют лимиты на:
- размер принимаемого текста JSON
- максимальный уровень вложенности объектов и массивов JSON
- диапазон и точность чисел JSON
- содержание и максимальная длина строк JSON
Этот модуль не ставит никаких ограничений, кроме тех, которые относятся к соответствующим типам Python или самому интерпретатору Python.
При сериализации в JSON будьте осторожны с такими ограничениями в приложениях, которые могут потреблять ваш JSON. В частности, числа в JSON часто десериализуются в числа двойной точности IEEE 754 и подвержены ограничениям диапазона и точности этого представления. Это особенно актуально при сериализации значений Python чрезвычайно большой величины или при сериализации экземпляров «необычных» числовых типов, таких как .