Класс str() в python, преобразует объект в строку
Содержание:
- Python string rfind()
- Проверяет, что все элементы в последовательности True.
- Разделить строки?
- Escape Characters
- Built-in String Methods
- Python NumPy
- Поисковые системы
- Python Tutorial
- Бинарный поиск
- Позиции файла
- BFS или DFS?
- А форматирование строк?
- Python string index()
- Находим множественные совпадения
- Вводная информация о строках
- Где находится автозамена в ворде
- Включение функции
Python string rfind()
The Python function rfind() is similar to find() function with the only difference is that rfind() gives the highest index for the substring given and find() gives the lowest i.e the very first index. Both rfind() and find() will return -1 if the substring is not present.
In the example below, we have a string «Meet Guru99 Tutorials Site. Best site for Python Tutorials!» and will try to find the position of substring Tutorials using find() and rfind(). The occurrence of Tutorials in the string is twice.
Here is an example where both find() and rfind() are used.
mystring = "Meet Guru99 Tutorials Site.Best site for Python Tutorials!"
print("The position of Tutorials using find() : ", mystring.find("Tutorials"))
print("The position of Tutorials using rfind() : ", mystring.rfind("Tutorials"))
Output:
The position of Tutorials using find() : 12 The position of Tutorials using rfind() : 48
The output shows that find() gives the index of the very first Tutorials substring that it gets, and rfind() gives the last index of substring Tutorials.
Проверяет, что все элементы в последовательности True.
Описание:
Функция возвращает значение , если все элементы в итерируемом объекте — истинны, в противном случае она возвращает значение .
Если передаваемая последовательность пуста, то функция также возвращает .
Функция применяется для проверки на ВСЕХ значений в последовательности и эквивалентна следующему коду:
def all(iterable):
for element in iterable
if not element
return False
return True
Так же смотрите встроенную функцию
В основном функция применяется в сочетании с оператором ветвления программы . Работу функции можно сравнить с оператором в Python, только работает с последовательностями:
>>> True and True and True # True >>> True and False and True # False >>> all() # True >>> all() # False
Но между и в Python есть два основных различия:
- Синтаксис.
- Возвращаемое значение.
Функция всегда возвращает или (значение )
>>> all() # True >>> all(]) # False
Если в выражении все значения , то оператор возвращает ПЕРВОЕ истинное значение, а если все значения , то последнее ложное значение. А если в выражении присутствует значение , то ПЕРВОЕ ложное значение. Что бы добиться поведения как у функции , необходимо выражение с оператором обернуть в функцию .
>>> 3 and 1 and 2 and 6 # 6 >>> 3 and and 3 and [] # 0 >>> bool(3 and 1 and 2 and 6) # True >>> bool(3 and and 3 and []) # False
Из всего сказанного можно сделать вывод, что для успешного использования функции необходимо в нее передавать последовательность, полученную в результате каких то вычислений/сравнений, элементы которого будут оцениваться как или . Это можно достичь применяя функцию или выражения-генераторы списков, используя в них встроенные функции или методы, возвращающие значения, операции сравнения, оператор вхождения и оператор идентичности .
num = 1, 2.0, 3.1, 4, 5, 6, 7.9 # использование встроенных функций или # методов на примере 'isdigit()' >>> str(x).isdigit() for x in num # # использование операции сравнения >>> x > 4 for x in num # # использование оператора вхождения `in` >>> '.' in str(x) for x in num # # использование оператора идентичности `is` >>> type(x) is int for x in num # # использование функции map() >>> list(map(lambda x x > 1, num)) False, True, True, True, True, True, True
Примеры проводимых проверок функцией .
Допустим, у нас есть список чисел и для дальнейших операций с этой последовательностью необходимо знать, что все числа например положительные.
>>> num1 = range(1, 9) >>> num2 = range(-1, 7) >>> all() # True >>> all() # False
Или проверить, что последовательность чисел содержит только ЦЕЛЫЕ числа.
>>> num1 = 1, 2, 3, 4, 5, 6, 7 >>> num2 = 1, 2.0, 3.1, 4, 5, 6, 7.9 >>> all() # True >>> all() # False
Или есть строка с числами, записанными через запятую и нам необходимо убедится, что в строке действительно записаны только цифры. Для этого, сначала надо разбить строку на список строк по разделителю и проверить каждый элемент полученного списка на десятичное число методом . Что бы учесть правила записи десятичных чисел будем убирать точку перед проверкой строки на десятичное число.
>>> line1 = "1, 2, 3, 9.9, 15.1, 7" >>> line2 = "1, 2, 3, 9.9, 15.1, 7, девять" >>> all() # True >>> all() # False
Еще пример со строкой. Допустим нам необходимо узнать, есть ли в строке наличие открытой И закрытой скобки?
Разделить строки?
Есть несколько способов получить часть строки. Первый — это , обратный метод для . В отличие от ’а, он применяется к целевой строке, а разделитель передаётся аргументом.
Второй — срезы (slices).
Срез s позволяет получить подстроку с символа x до символа y. Можно не указывать любое из значений, чтобы двигаться с начала или до конца строки. Отрицательные значения используются для отсчёта с конца (-1 — последний символ, -2 — предпоследний и т.п.).
При помощи необязательного третьего параметра s можно выбрать из подстроки каждый N-ый символ. Например, получить только чётные или только нечётные символы:
Escape Characters
Following table is a list of escape or non-printable characters that can be represented with backslash notation.
An escape character gets interpreted; in a single quoted as well as double quoted strings.
| Backslash notation | Hexadecimal character | Description |
|---|---|---|
| \a | 0x07 | Bell or alert |
| \b | 0x08 | Backspace |
| \cx | Control-x | |
| \C-x | Control-x | |
| \e | 0x1b | Escape |
| \f | 0x0c | Formfeed |
| \M-\C-x | Meta-Control-x | |
| \n | 0x0a | Newline |
| \nnn | Octal notation, where n is in the range 0.7 | |
| \r | 0x0d | Carriage return |
| \s | 0x20 | Space |
| \t | 0x09 | Tab |
| \v | 0x0b | Vertical tab |
| \x | Character x | |
| \xnn | Hexadecimal notation, where n is in the range 0.9, a.f, or A.F |
Built-in String Methods
Python includes the following built-in methods to manipulate strings −
| Sr.No. | Methods with Description |
|---|---|
| 1 |
capitalize()
Capitalizes first letter of string |
| 2 |
center(width, fillchar)
Returns a space-padded string with the original string centered to a total of width columns. |
| 3 |
count(str, beg= 0,end=len(string))
Counts how many times str occurs in string or in a substring of string if starting index beg and ending index end are given. |
| 4 |
decode(encoding=’UTF-8′,errors=’strict’)
Decodes the string using the codec registered for encoding. encoding defaults to the default string encoding. |
| 5 |
encode(encoding=’UTF-8′,errors=’strict’)
Returns encoded string version of string; on error, default is to raise a ValueError unless errors is given with ‘ignore’ or ‘replace’. |
| 6 |
endswith(suffix, beg=0, end=len(string))
Determines if string or a substring of string (if starting index beg and ending index end are given) ends with suffix; returns true if so and false otherwise. |
| 7 |
expandtabs(tabsize=8)
Expands tabs in string to multiple spaces; defaults to 8 spaces per tab if tabsize not provided. |
| 8 |
find(str, beg=0 end=len(string))
Determine if str occurs in string or in a substring of string if starting index beg and ending index end are given returns index if found and -1 otherwise. |
| 9 |
index(str, beg=0, end=len(string))
Same as find(), but raises an exception if str not found. |
| 10 |
isalnum()
Returns true if string has at least 1 character and all characters are alphanumeric and false otherwise. |
| 11 |
isalpha()
Returns true if string has at least 1 character and all characters are alphabetic and false otherwise. |
| 12 |
isdigit()
Returns true if string contains only digits and false otherwise. |
| 13 |
islower()
Returns true if string has at least 1 cased character and all cased characters are in lowercase and false otherwise. |
| 14 |
isnumeric()
Returns true if a unicode string contains only numeric characters and false otherwise. |
| 15 |
isspace()
Returns true if string contains only whitespace characters and false otherwise. |
| 16 |
istitle()
Returns true if string is properly «titlecased» and false otherwise. |
| 17 |
isupper()
Returns true if string has at least one cased character and all cased characters are in uppercase and false otherwise. |
| 18 |
join(seq)
Merges (concatenates) the string representations of elements in sequence seq into a string, with separator string. |
| 19 |
len(string)
Returns the length of the string |
| 20 |
ljust(width)
Returns a space-padded string with the original string left-justified to a total of width columns. |
| 21 |
lower()
Converts all uppercase letters in string to lowercase. |
| 22 |
lstrip()
Removes all leading whitespace in string. |
| 23 |
maketrans()
Returns a translation table to be used in translate function. |
| 24 |
max(str)
Returns the max alphabetical character from the string str. |
| 25 |
min(str)
Returns the min alphabetical character from the string str. |
| 26 |
replace(old, new )
Replaces all occurrences of old in string with new or at most max occurrences if max given. |
| 27 |
rfind(str, beg=0,end=len(string))
Same as find(), but search backwards in string. |
| 28 |
rindex( str, beg=0, end=len(string))
Same as index(), but search backwards in string. |
| 29 |
rjust(width,)
Returns a space-padded string with the original string right-justified to a total of width columns. |
| 30 |
rstrip()
Removes all trailing whitespace of string. |
| 31 |
split(str=»», num=string.count(str))
Splits string according to delimiter str (space if not provided) and returns list of substrings; split into at most num substrings if given. |
| 32 |
splitlines( num=string.count(‘\n’))
Splits string at all (or num) NEWLINEs and returns a list of each line with NEWLINEs removed. |
| 33 |
startswith(str, beg=0,end=len(string))
Determines if string or a substring of string (if starting index beg and ending index end are given) starts with substring str; returns true if so and false otherwise. |
| 34 |
strip()
Performs both lstrip() and rstrip() on string. |
| 35 |
swapcase()
Inverts case for all letters in string. |
| 36 |
title()
Returns «titlecased» version of string, that is, all words begin with uppercase and the rest are lowercase. |
| 37 |
translate(table, deletechars=»»)
Translates string according to translation table str(256 chars), removing those in the del string. |
| 38 |
upper()
Converts lowercase letters in string to uppercase. |
| 39 |
zfill (width)
Returns original string leftpadded with zeros to a total of width characters; intended for numbers, zfill() retains any sign given (less one zero). |
| 40 |
isdecimal()
Returns true if a unicode string contains only decimal characters and false otherwise. |
Previous Page
Print Page
Next Page
Python NumPy
NumPy IntroNumPy Getting StartedNumPy Creating ArraysNumPy Array IndexingNumPy Array SlicingNumPy Data TypesNumPy Copy vs ViewNumPy Array ShapeNumPy Array ReshapeNumPy Array IteratingNumPy Array JoinNumPy Array SplitNumPy Array SearchNumPy Array SortNumPy Array FilterNumPy Random
Random Intro
Data Distribution
Random Permutation
Seaborn Module
Normal Distribution
Binomial Distribution
Poisson Distribution
Uniform Distribution
Logistic Distribution
Multinomial Distribution
Exponential Distribution
Chi Square Distribution
Rayleigh Distribution
Pareto Distribution
Zipf Distribution
NumPy ufunc
ufunc Intro
ufunc Create Function
ufunc Simple Arithmetic
ufunc Rounding Decimals
ufunc Logs
ufunc Summations
ufunc Products
ufunc Differences
ufunc Finding LCM
ufunc Finding GCD
ufunc Trigonometric
ufunc Hyperbolic
ufunc Set Operations
Поисковые системы
Python Tutorial
Python HOMEPython IntroPython Get StartedPython SyntaxPython CommentsPython Variables
Python Variables
Variable Names
Assign Multiple Values
Output Variables
Global Variables
Variable Exercises
Python Data TypesPython NumbersPython CastingPython Strings
Python Strings
Slicing Strings
Modify Strings
Concatenate Strings
Format Strings
Escape Characters
String Methods
String Exercises
Python BooleansPython OperatorsPython Lists
Python Lists
Access List Items
Change List Items
Add List Items
Remove List Items
Loop Lists
List Comprehension
Sort Lists
Copy Lists
Join Lists
List Methods
List Exercises
Python Tuples
Python Tuples
Access Tuples
Update Tuples
Unpack Tuples
Loop Tuples
Join Tuples
Tuple Methods
Tuple Exercises
Python Sets
Python Sets
Access Set Items
Add Set Items
Remove Set Items
Loop Sets
Join Sets
Set Methods
Set Exercises
Python Dictionaries
Python Dictionaries
Access Items
Change Items
Add Items
Remove Items
Loop Dictionaries
Copy Dictionaries
Nested Dictionaries
Dictionary Methods
Dictionary Exercise
Python If…ElsePython While LoopsPython For LoopsPython FunctionsPython LambdaPython ArraysPython Classes/ObjectsPython InheritancePython IteratorsPython ScopePython ModulesPython DatesPython MathPython JSONPython RegExPython PIPPython Try…ExceptPython User InputPython String Formatting
Бинарный поиск
Бинарный поиск работает по принципу «разделяй и властвуй». Он быстрее, чем линейный поиск, но требует, чтобы массив был отсортирован перед выполнением алгоритма.
Предполагая, что мы ищем значение в отсортированном массиве, алгоритм сравнивает со значением среднего элемента массива, который мы будем называть .
- Если — это тот элемент, который мы ищем (в лучшем случае), мы возвращаем его индекс.
- Если нет, мы определяем, в какой половине массива мы будем искать дальше, основываясь на том, меньше или больше значение значения , и отбрасываем вторую половину массива.
- Затем мы рекурсивно или итеративно выполняем те же шаги, выбирая новое значение для , сравнивая его с и отбрасывая половину массива на каждой итерации алгоритма.
Алгоритм бинарного поиска можно написать как рекурсивно, так и итеративно. , потому что она требует выделения новых кадров стека.
Поскольку хороший алгоритм поиска должен быть максимально быстрым и точным, давайте рассмотрим итеративную реализацию бинарного поиска:
def BinarySearch(lys, val):
first = 0
last = len(lys)-1
index = -1
while (first <= last) and (index == -1):
mid = (first+last)//2
if lys == val:
index = mid
else:
if val<lys:
last = mid -1
else:
first = mid +1
return index
Если мы используем функцию для вычисления:
>>> BinarySearch(, 20)
То получим следующий результат, являющийся индексом искомого значения:
1
На каждой итерации алгоритм выполняет одно из следующих действий:
- Возврат индекса текущего элемента.
- Поиск в левой половине массива.
- Поиск в правой половине массива.
Мы можем выбрать только одно действие на каждой итерации. Также на каждой итерации наш массив делится на две части. Из-за этого временная сложность двоичного поиска равна O(log n).
Одним из недостатков бинарного поиска является то, что если в массиве имеется несколько вхождений элемента, он возвращает индекс не первого элемента, а ближайшего к середине:
>>> print(BinarySearch(, 4))
После выполнения этого фрагмента кода будет возвращен индекс среднего элемента:
2
Для сравнения: выполнение линейного поиска по тому же массиву вернет индекс первого элемента:
Однако мы не можем категорически утверждать, что двоичный поиск не работает, если массив содержит дубликаты. Он может работать так же, как линейный поиск, и в некоторых случаях возвращать первое вхождение элемента. Например:
>>> print(BinarySearch(, 4)) 3
Бинарный поиск довольно часто используется на практике, потому что он эффективен и быстр по сравнению с линейным поиском. Однако у него есть некоторые недостатки, такие как зависимость от оператора . Существует много других алгоритмов поиска, работающих по принципу «разделяй и властвуй», которые являются производными от бинарного поиска. Некоторые из них мы рассмотрим далее.
Позиции файла
Метод tell указывает вам на текущую позицию в файле; Другими словами, следующее чтение или запись будет происходить на столько байтов от начала файла.
Метод seek(offset) изменяет текущую позицию в файле. Аргумент offset указывает число байтов, которые будут перемещены. Аргумент from определяет базисную позицию, откуда байты должны быть перемещены.
Если from установлено значение 0, то начало файла используется в качестве опорной позиции. Если он установлен в 1, то текущее положение используется в качестве опорной позиции. Если установлено значение 2, то конец файла будет принят в качестве опорной позиции.
Пример
Возьмем файл andreyex.txt, который мы создали выше.
#!/usr/bin/python3
# Открыть файл
fo = open("andreyex.txt", "r+")
str = fo.read(10)
print ("Читать строку : ", str)
# Проверить текущую позицию
position = fo.tell()
print ("Текущая позиция файла : ", position)
# Переместите указатель в начало еще раз
position = fo.seek(0, 0)
str = fo.read(12)
print ("Снова считать строку : ", str)
# Закрыть открытый файл
fo.close()
Это приводит к следующему результату:
Читать строку : Python - это Текущая позиция файла : 12 Снова считать строку : Python - это
BFS или DFS?
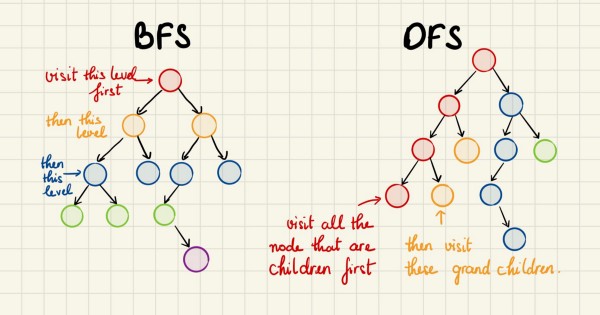
Вот мы и рассмотрели отличия DFS и BFS. Вам наверняка также интересно узнать, когда и какой из них подходит лучше. На ранней стадии изучения алгоритмов я тоже задавался этим вопросом. Надеюсь, мой ответ сможет дать достаточное пояснение:
- Если нам известно, что искомая точка находится недалеко от корня, то лучше использовать BFS.
- Если дерево имеет очень глубокую структуру, а искомые точки в нём редки, то DFS может потребовать очень много времени. BFS же справится быстрее.
- Если дерево очень широкое, то BFS может потребовать так много памяти, что утратит свою практичность.
- Если искомые точки встречаются часто, но расположены в глубине дерева, BFS может также оказаться непрактичным.
Обычно стоит использовать:
- BFS, когда нужно найти кратчайший путь от конкретного исходного узла к нужной точке. Иначе говоря, когда нас интересует путь с наименьшим числом шагов, ведущих от заданного начального состояния к искомому.
- DFS, когда нужно исследовать все возможности и найти наилучшую либо пересчитать количество возможных путей.
- BFS или DFS, когда нужно только проверить наличие связи между двумя узлами представленного графа или, иначе говоря, узнать, можем ли мы достичь одного, находясь в другом.
А форматирование строк?
Типичная жизненная необходимость — сформировать строку, подставив в неё результат работы программы. Начиная с Python 3.6, это можно делать при помощи f-строк:
В более старом коде можно встретить альтернативные способы
Технически можно было обойтись склейкой, но это менее элегантно, а еще придётся следить, чтобы все склеиваемые кусочки были строками. Не рекомендую:
***
Цель работодателя на собеседовании — убедиться что вы соображаете и что вы справитесь с реальными задачами. Однако погружение в реальные задачи занимает несколько недель, а время интервью ограничено. Поэтому вас ждут учебные задания, которые можно решить за 10-30 минут, а также вопросы на понимание того, как работает код. О них и поговорим в следующей части.
Python string index()
The Python string index() is function that will give you the position of the substring given just like find(). The only difference between the two is, index() will throw an exception if the substring is not present in the string and find() will return -1.
Here is a working example that shows the behaviour of index() and find().
mystring = "Meet Guru99 Tutorials Site.Best site for Python Tutorials!"
print("The position of Tutorials using find() : ", mystring.find("Tutorials"))
print("The position of Tutorials using index() : ", mystring.index("Tutorials"))
Output:
The position of Tutorials using find() : 12 The position of Tutorials using index() : 12
We are getting same position for both find() and index(). Let us see an example when the substring given is not present in the string.
mystring = "Meet Guru99 Tutorials Site.Best site for Python Tutorials!"
print("The position of Tutorials using find() : ", mystring.find("test"))
print("The position of Tutorials using index() : ", mystring.index("test"))
Output:
The position of Tutorials using find() : -1
Traceback (most recent call last):
File "task1.py", line 3, in <module>
print("The position of Tutorials using index() : ", mystring.index("test"))
ValueError: substring not found
In the above example, we are trying to find the position of substring «test». The substring is not present in the given string, and hence using find(), we get the position as -1, but for index(), it throws an error as shown above.
Находим множественные совпадения
До этого момента мы научились только находить первое совпадение в строке. Но что если у вас строка, в которой содержится множество совпадений? Давайте посмотрим, как найти одно:
Python
import re
silly_string = «the cat in the hat»
pattern = «the»
match = re.search(pattern, text)
print(match.group()) # ‘the’
|
1 |
importre silly_string=»the cat in the hat» pattern=»the» match=re.search(pattern,text) print(match.group())# ‘the’ |
Теперь, как вы видите, у нас есть два экземпляра слова the, но нашли мы только одно. Существует два метода, чтобы найти все совпадения. Первый, который мы рассмотрим, это использование функции findall:
Python
import re
silly_string = «the cat in the hat»
pattern = «the»
a = re.findall(pattern, silly_string)
print(a) #
|
1 |
importre silly_string=»the cat in the hat» pattern=»the» a=re.findall(pattern,silly_string) print(a)# |
Функция findall будет искать по всей переданной ей строке, и впишет каждое совпадение в список. По окончанию поиска вышей строки, она выдаст список совпадений. Второй способ найти несколько совпадений, это использовать функцию finditer:
Python
import re
silly_string = «the cat in the hat»
pattern = «the»
for match in re.finditer(pattern, silly_string):
s = «Found ‘{group}’ at {begin}:{end}».format(
group=match.group(), begin=match.start(),
end=match.end())
print(s)
|
1 |
importre silly_string=»the cat in the hat» pattern=»the» formatch inre.finditer(pattern,silly_string) s=»Found ‘{group}’ at {begin}:{end}».format( group=match.group(),begin=match.start(), end=match.end()) print(s) |
Как вы могли догадаться, метод finditer возвращает итератор экземпляров Match, вместо строк, которые мы получаем от findall. Так что нам нужно немного подформатировать результаты перед их выводом. Попробуйте запустить данный код и посмотрите, как он работает.
Вводная информация о строках
Как и во многих других языках программирования, в Python есть большая коллекция функций, операторов и методов, позволяющих работать со строковым типом.
Литералы строк
Литерал – способ создания объектов, в случае строк Питон предлагает несколько основных вариантов:
Если внутри строки необходимо расположить двойные кавычки, и сама строка была создана с помощью двойных кавычек, можно сделать следующее:
Разницы между строками с одинарными и двойными кавычками нет – это одно и то же
Какие кавычки использовать – решать вам, соглашение PEP 8 не дает рекомендаций по использованию кавычек. Просто выберите один тип кавычек и придерживайтесь его. Однако если в стоке используются те же кавычки, что и в литерале строки, используйте разные типы кавычек – обратная косая черта в строке ухудшает читаемость кода.
Кодировка строк
В третьей версии языка программирования Python все строки представляют собой последовательность Unicode-символов.
В Python 3 кодировка по умолчанию исходного кода – UTF-8. Во второй версии по умолчанию использовалась ASCII. Если необходимо использовать другую кодировку, можно разместить специальное объявление на первой строке файла, к примеру:
Максимальная длина строки в Python
Максимальная длина строки зависит от платформы. Обычно это:
- 2**31 — 1 – для 32-битной платформы;
- 2**63 — 1 – для 64-битной платформы;
Константа , определенная в модуле
Конкатенация строк
Одна из самых распространенных операций со строками – их объединение (конкатенация). Для этого используется знак , в результате к концу первой строки будет дописана вторая:
При необходимости объединения строки с числом его предварительно нужно привести тоже к строке, используя функцию
Сравнение строк
При сравнении нескольких строк рассматриваются отдельные символы и их регистр:
- цифра условно меньше, чем любая буква из алфавита;
- алфавитная буква в верхнем регистре меньше, чем буква в нижнем регистре;
- чем раньше буква в алфавите, тем она меньше;
При этом сравниваются по очереди первые символы, затем – 2-е и так далее.
Далеко не всегда желательной является зависимость от регистра, в таком случае можно привести обе строки к одному и тому же регистру. Для этого используются функции – для приведения к нижнему и – к верхнему:
Как удалить строку в Python
Строки, как и некоторые другие типы данных в языке Python, являются неизменяемыми объектами. При задании нового значения строке просто создается новая, с заданным значением. Для удаления строки можно воспользоваться методом , заменив ее на пустую строку:
Или перезаписать переменную пустой строкой:
Обращение по индексу
Для выбора определенного символа из строки можно воспользоваться обращением по индексу, записав его в квадратных скобках:
Индекс начинается с 0
В Python предусмотрена возможность получить доступ и по отрицательному индексу. В таком случае отсчет будет вестись от конца строки:
Где находится автозамена в ворде
Включение функции
Чтобы включить в текстовом редакторе автозамену слова, следует перейти во вкладку «Файл». Она располагается на верхней панели задач в верхнем левом углу.
В открывшемся окне, требуется выбрать пункт «Параметры», который находится в левой колонке почти в самом низу списка.
После выполнения описанных функций откроется меню, в котором необходимо перейти в раздел «Правописание» и нажать на кнопку «Параметры автозамены».
В открытом окне следует ввести следующие параметры:
- во вкладке «Автозамена» выбрать пункт «Заменить при вводе»;
- в строчке «Заменить» указать неверное написание слова;
- в графе «На» ввести выражение, на которое должна происходить замена;
- после введения требуемых слов, требуется нажать кнопку «Добавить»;
- установить галочку у пункта «Автоматически заменять орфографические ошибки».
Завершающим этапом будет нажатие на кнопку «Ок», для подтверждения внесенных в настройках изменений.
Данная функция уже оснащена основным набором слов и исправлений, но при необходимости, список можно создать под себя вручную.
Также некоторые слова из данного списка можно убирать, кликнув по ним один раз и нажав кнопку «Удалить».