Bash-скрипты, часть 9: регулярные выражения
Содержание:
- Введение в регулярные выражения
- Literal Characters
- Синтаксис регулярных выражений
- Lookaround
- Grabbing HTML Tags
- Применение в Google Analytics
- Символьные классы — \d \w \s и .
- Нечёткие регулярные выражения
- 2.8.1 Caret
- Максимализм и минимализм
- Unicode категории (category)¶
- Литература
- Поиск совпадений: метод exec
- 2 Практический раздел. Ссылки
Введение в регулярные выражения
Язык регулярных выражений предназначен специально для обработки строк. Он включает два средства:
-
Набор управляющих кодов для идентификации специфических типов символов
-
Система для группирования частей подстрок и промежуточных результатов таких действий
С помощью регулярных выражений можно выполнять достаточно сложные и высокоуровневые действия над строками:
-
Идентифицировать (и возможно, помечать к удалению) все повторяющиеся слова в строке
-
Сделать заглавными первые буквы всех слов
-
Преобразовать первые буквы всех слов длиннее трех символов в заглавные
-
Обеспечить правильную капитализацию предложений
-
Выделить различные элементы в URI (например, имея http://www.professorweb.ru, выделить протокол, имя компьютера, имя файла и т.д.)
Главным преимуществом регулярных выражений является использование метасимволов — специальные символы, задающие команды, а также управляющие последовательности, которые работают подобно управляющим последовательностям C#. Это символы, предваренные знаком обратного слеша (\) и имеющие специальное назначение.
В следующей таблице специальные метасимволы регулярных выражений C# сгруппированы по смыслу:
Метасимволы, используемые в регулярных выражениях C#
Символ
Значение
Пример
Соответствует
Классы символов
Любой из символов, указанных в скобках
В исходной строке может быть любой символ английского алфавита в нижнем регистре
Любой из символов, не указанных в скобках
В исходной строке может быть любой символ кроме цифр
.
Любой символ, кроме перевода строки или другого разделителя Unicode-строки
\w
Любой текстовый символ, не являющийся пробелом, символом табуляции и т.п.
\W
Любой символ, не являющийся текстовым символом
\s
Любой пробельный символ из набора Unicode
\S
Любой непробельный символ из набора Unicode
Обратите внимание, что символы \w и \S — это не одно и то же
\d
Любые ASCII-цифры. Эквивалентно
\D
Любой символ, отличный от ASCII-цифр
Эквивалентно
Символы повторения
{n,m}
Соответствует предшествующему шаблону, повторенному не менее n и не более m раз
s{2,4}
«Press», «ssl», «progressss»
{n,}
Соответствует предшествующему шаблону, повторенному n или более раз
s{1,}
«ssl»
{n}
Соответствует в точности n экземплярам предшествующего шаблона
s{2}
«Press», «ssl», но не «progressss»
?
Соответствует нулю или одному экземпляру предшествующего шаблона; предшествующий шаблон является необязательным
Эквивалентно {0,1}
+
Соответствует одному или более экземплярам предшествующего шаблона
Эквивалентно {1,}
*
Соответствует нулю или более экземплярам предшествующего шаблона
Эквивалентно {0,}
Символы регулярных выражений выбора
|
Соответствует либо подвыражению слева, либо подвыражению справа (аналог логической операции ИЛИ).
(…)
Группировка. Группирует элементы в единое целое, которое может использоваться с символами *, +, ?, | и т.п. Также запоминает символы, соответствующие этой группе для использования в последующих ссылках.
(?:…)
Только группировка. Группирует элементы в единое целое, но не запоминает символы, соответствующие этой группе.
Якорные символы регулярных выражений
^
Соответствует началу строкового выражения или началу строки при многострочном поиске.
^Hello
«Hello, world», но не «Ok, Hello world» т.к. в этой строке слово «Hello» находится не в начале
$
Соответствует концу строкового выражения или концу строки при многострочном поиске.
Hello$
«World, Hello»
\b
Соответствует границе слова, т.е. соответствует позиции между символом \w и символом \W или между символом \w и началом или концом строки.
\b(my)\b
В строке «Hello my world» выберет слово «my»
\B
Соответствует позиции, не являющейся границей слов.
\B(ld)\b
Соответствие найдется в слове «World», но не в слове «ld»
Literal Characters
The most basic regular expression consists of a single literal character, such as a. It matches the first occurrence of that character in the string. If the string is Jack is a boy, it matches the a after the J.
This regex can match the second a too. It only does so when you tell the regex engine to start searching through the string after the first match. In a text editor, you can do so by using its “Find Next” or “Search Forward” function. In a programming language, there is usually a separate function that you can call to continue searching through the string after the previous match.
Twelve characters have special meanings in regular expressions: the backslash \, the caret ^, the dollar sign $, the period or dot ., the vertical bar or pipe symbol |, the question mark ?, the asterisk or star *, the plus sign +, the opening parenthesis (, the closing parenthesis ), the opening square bracket , and the opening curly brace {. These special characters are often called “metacharacters”. Most of them are errors when used alone.
If you want to use any of these characters as a literal in a regex, you need to escape them with a backslash. If you want to match 1+1=2, the correct regex is 1\+1=2. Otherwise, the plus sign has a special meaning.
Синтаксис регулярных выражений
Последнее обновление: 1.11.2015
Рассмотрим базовые моменты синтаксиса регулярных выражений.
Метасимволы
Регулярные выражения также могут использовать метасимволы — символы, которые имеют определенный смысл:
-
: соответствует любой цифре от 0 до 9
-
: соответствует любому символу, который не является цифрой
-
: соответствует любой букве, цифре или символу подчеркивания (диапазоны A–Z, a–z, 0–9)
-
: соответствует любому символу, который не является буквой, цифрой или символом подчеркивания (то есть не находится в следующих диапазонах A–Z, a–z, 0–9)
-
: соответствует пробелу
-
: соответствует любому символу, который не является пробелом
-
: соответствует любому символу
Здесь надо заметить, что метасимвол \w применяется только для букв латинского алфавита, кириллические символы для него не подходят.
Так, стандартный формат номера телефона соответствует регулярному выражению .
Например, заменим числа номера нулями:
var phoneNumber = «+1-234-567-8901»; var myExp = /\d-\d\d\d-\d\d\d-\d\d\d\d/; phoneNumber = phoneNumber.replace(myExp, «00000000000»); document.write(phoneNumber);
Модификаторы
Кроме выше рассмотренных элементов регулярных выражений есть еще одна группа комбинаций, которая указывает, как символы в строке будут повторяться. Такие комбинации еще называют модификаторами:
-
: соответствует n-ому количеству повторений предыдущего символа. Например, соответствует подстроке «hhh»
-
: соответствует n и более количеству повторений предыдущего символа. Например, соответствует подстрокам «hhh», «hhhh», «hhhhh» и т.д.
-
: соответствует от n до m повторений предыдущего символа. Например, соответствует подстрокам «hh», «hhh», «hhhh».
-
: соответствует одному вхождению предыдущего символа в подстроку или его отсутствию в подстроке. Например, соответствует подстрокам «home» и «ome».
-
: соответствует одному и более повторений предыдущего символа
-
: соответствует любому количеству повторений или отсутствию предыдущего символа
-
: соответствует началу строки.
Например, соответствует строке «home», но не «ohma», так как h должен представлять начало строки
-
: соответствует концу строки. Например, соответствует строке «дом», так как строка должна оканчиваться на букву м
Например, возьмем номер тот же телефона. Ему соответствует регулярное выражение . Однако с помощью выше рассмотренных комбинаций мы его можем упростить:
Также надо отметить, что так как символы ?, +, * имеют особый смысл в регулярных выражениях, то чтобы их использовать в обычным для них значении (например, нам надо заменить знак плюс в строке на минус), то данные символы надо экранировать с помощью слеша:
var phoneNumber = «+1-234-567-8901»; var myExp = /\+\d-\d{3}-\d{3}-\d{4}/; phoneNumber = phoneNumber.replace(myExp, «80000000000»); document.write(phoneNumber);
Отдельно рассмотрим применение комбинации ‘\b’, которая указывает на соответствие в пределах слова. Например, у нас есть следующая строка: «Языки обучения: Java, JavaScript, C++». Со временем мы решили, что Java надо заменить на C#. Но простая замена приведет также к замене строки «JavaScript» на «C#Script», что недопустимо. И в этом случае мы можем проводить замену, если регуляное выражение соответствует всему слову:
var initialText = «Языки обучения: Java, JavaScript, C++»; var exp = /Java\b/g; var result = initialText.replace(exp, «C#»); document.write(result); // Языки обучения: C#, JavaScript, C++
Но при использовании ‘\b’ надо учитывать, что в JavaScript отсутствует полноценная поддержка юникода, поэтому применять ‘\b’ мы сможем только к англоязычным словам.
Использование групп в регулярных выражениях
Для поиска в строке более сложных соответствий применяются группы. В регулярных выражениях группы заключаются в скобки. Например, у нас есть следующий код html, который содержит тег изображения: ‘<img src=»https://steptosleep.ru/wp-content/uploads/2018/06/47616.png» />’. И допустим, нам надо вычленить из этого кода пути к изображениям:
var initialText = ‘<img src= «picture.png» />’; var exp = /+\.(png|jpg)/i; var result = initialText.match(exp); result.forEach(function(value, index, array){ document.write(value + «<br/>»); })
Вывод браузера:
picture.png png
Первая часть до скобок (+\.) указывает на наличие в строке от 1 и более символов из диапазона a-z, после которых идет точка. Так как точка является специальным символом в регулярных выражениях, то она экранируется слешем. А дальше идет группа: . Эта группа указывает, что после точки может использоваться как «png», так и «jpg».
Lookaround
Lookaround is a special kind of group. The tokens inside the group are matched normally, but then the regex engine makes the group give up its match and keeps only the result. Lookaround matches a position, just like anchors. It does not expand the regex match.
q(?=u) matches the q in question, but not in Iraq. This is positive lookahead. The u is not part of the overall regex match. The lookahead matches at each position in the string before a u.
q(?!u) matches q in Iraq but not in question. This is negative lookahead. The tokens inside the lookahead are attempted, their match is discarded, and the result is inverted.
To look backwards, use lookbehind. The positive lookbehind (?<=a)b matches the b in abc. The negative lookbehind (?<!a)b fails to match abc.
You can use a full-fledged regular expression inside lookahead. Most applications only allow fixed-length expressions in lookbehind.
Grabbing HTML Tags
<TAG\b^>*>(.*?)</TAG> matches the opening and closing pair of a specific HTML tag. Anything between the tags is captured into the first backreference. The question mark in the regex makes the star lazy, to make sure it stops before the first closing tag rather than before the last, like a greedy star would do. This regex will not properly match tags nested inside themselves, like in <TAG>one<TAG>two</TAG>one</TAG>.
<(A-ZA-Z-9*)\b^>*>(.*?)</\1> will match the opening and closing pair of any HTML tag. Be sure to turn off case sensitivity. The key in this solution is the use of the backreference \1 in the regex. Anything between the tags is captured into the second backreference. This solution will also not match tags nested in themselves.
Применение в Google Analytics
Регулярные выражения в Google Analytics чаще всего используют для настройки целей, фильтров, отчетов, сегментов и аудиторий. Давайте разберем несколько примеров.
У клиента на сайте было две формы заявок, после заполнения которых открывались две разные страницы с благодарностью. Чтобы не делать две отдельные цели, настраиваем одну через регулярные выражения: \/thank\/|\/send\-contact\.php.
-
\ — переводим «/» и «.» в обычные символы;
-
| — между страницами thank you page.
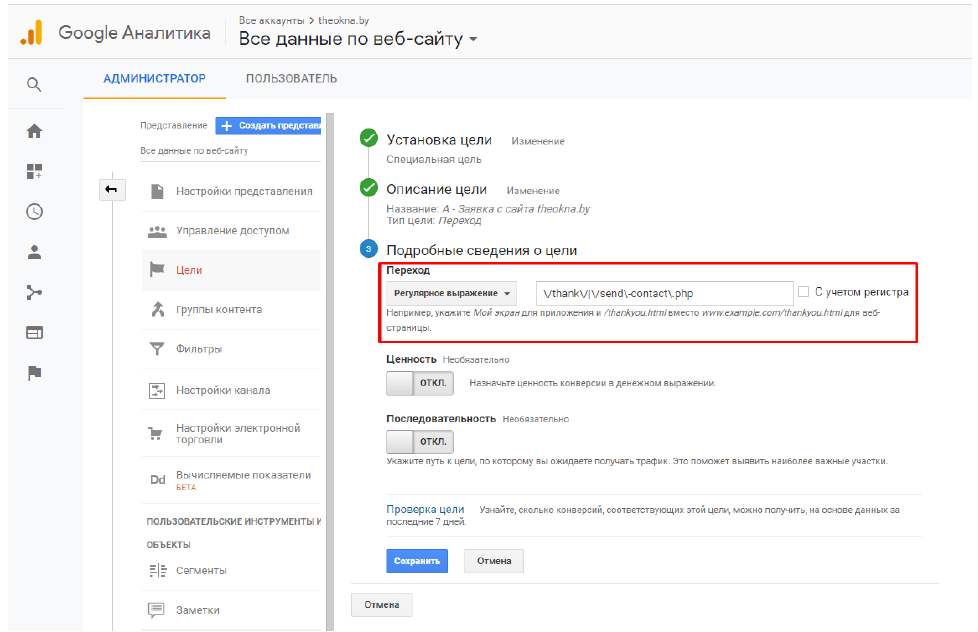 Пример использования регулярных выражений в Google Analytics для настройки цели
Пример использования регулярных выражений в Google Analytics для настройки цели
Вот еще один пример — про работу с отчетом по поисковым запросам. Допустим, нам нужно вывести в отчет только запросы, содержащие фразу «агентство интернет-маркетинга». Чтобы учесть все варианты написания слова «агентство» с ошибками и опечатками, используем выражение агент?ств, где:
-
т? означает, что предыдущий символ присутствует или отсутствует в тексте;
-
— присутствует любой из перечисленных символов;
 Использование регулярных выражений в отчете Google Analytics: фильтрация запросов
Использование регулярных выражений в отчете Google Analytics: фильтрация запросов
Аналогичный пример — отчет по поисковым запросам для компании, оформляющей филиппинские визы:
-
филип+ины: п+ означает предыдущий символ, присутствует один и более раз;
-
филип{1,2}ины: п{1,2} — предыдущий символ используется от 1 до 2 раз.
 Фильтрация запросов в Google Analytics
Фильтрация запросов в Google Analytics
С помощью регулярных выражений можно исключить трафик для определенного диапазона IP-адресов. Например, так: 178\.165\.69\.\d{1,3}
-
\ — переводим «.» в обычные символы;
-
\d{1,3} — выбрали все цифры, которые будут присутствовать от 1 до 3 раз, то есть, по сути, задали диапазон от 0 до 999 (хотя диапазон в IP-адресах от 0 до 255).
 Настройка фильтра по IP-адресам в Google Analytics
Настройка фильтра по IP-адресам в Google Analytics
И еще один вариант фильтрации IP-адресов: 178\.165\.69\.(1|200):
-
\ — переводим «.» в обычные символы;
-
(1|200) — выбрали числа от 100 до 199 или 200.
 Шаблон фильтра
Шаблон фильтра
Символьные классы — \d \w \s и .
\d соответствует одному символу, который является цифрой -> тест\w соответствует слову (может состоять из букв, цифр и подчёркивания) -> тест\s соответствует символу пробела (включая табуляцию и прерывание строки). соответствует любому символу -> тест
Используйте оператор с осторожностью, так как зачастую класс или отрицаемый класс символов (который мы рассмотрим далее) быстрее и точнее. У операторов , и также есть отрицания ― исоответственно
У операторов , и также есть отрицания ― исоответственно.
Например, оператор будет искать соответствия противоположенные .
\D соответствует одному символу, который не является цифрой -> тест
Некоторые символы, например , необходимо выделять обратным слешем .
\$\d соответствует строке, в которой после символа $ следует одна цифра -> тест
Непечатаемые символы также можно искать, например табуляцию , новую строку , возврат каретки .
Нечёткие регулярные выражения
В некоторых случаях регулярные выражения удобно применить для анализа текстовых фрагментов на естественном языке, то есть написанных людьми, и, возможно, содержащих опечатки либо нестандартные варианты употреблений слов. Например, если проводить опрос (допустим, на веб-сайте) «какой станцией метро вы пользуетесь», может оказаться, что «Невский проспект» посетители могут указать как:
- Невский
- Невск. просп.
- Нев. проспект
- наб. Канала Грибоедова («Канал Грибоедова» — это название второго выхода ст. м. Невский проспект)
Здесь обычные регулярные выражения неприменимы, в первую очередь из-за того, что входящие в образцы слова могут совпадать не очень точно (нечётко), но, тем не менее, было бы удобно описывать регулярными выражениями структурные зависимости между элементами образца,
например, в нашем случае, указать, что совпадение может быть с образцом «Невский проспект» ИЛИ «Канал Грибоедова», притом «проспект» может быть сокращено до «пр» или отсутствовать, а перед «Канал» может находиться сокращение «наб.»
Эта задача сродни полнотекстовому поиску, отличаясь в том, что здесь короткий фрагмент должен сравниваться с набором образцов, а при полнотекстовом поиске, наоборот, образец обычно один, в то время как фрагмент текста очень большой, или задаче разрешения лексической многозначности, которая, однако, не позволяет задать структурирующие отношения между элементами образца.
Существует небольшое количество библиотек, реализующих механизм регулярных выражений с возможностью нечёткого сравнения:
- TRE — бесплатная библиотека на С, использующая синтаксис регулярных выражений, похожий на POSIX (стабильный проект);
- FREJ — open-source библиотека на Java, использующая Lisp-образный синтаксис и лишённая многих возможностей обычных регулярных выражений, но сосредоточенная на различного рода автоматических заменах фрагментов текста (бета-версия).
2.8.1 Caret
Caret symbol is used to check if matching character is the first characterof the input string. If we apply the following regular expression (if a isthe starting symbol) to input string it matches . But if we apply regular expression on above input string it does not match anything. Because in input string is not the starting symbol. Let’s take a look at another regular expression which means: uppercase character or lowercase character is the start symbol of the input string, followed bylowercase character , followed by lowercase character .
(T|t)he => The car is parked in the garage.
^(T|t)he => The car is parked in the garage.
Максимализм и минимализм
Концепции максимализма и минимализма играют важную роль при написании регулярных выражений. Допустим, из разделенного запятыми списка имен нужно извлечь только первое имя и следующую за ним запятую. Список, уже приводившийся ранее, выглядит так:
names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron';
Казалось бы, нужно искать серию символов, завершающуюся запятой:
.*,
Давайте посмотрим, что из этого получится:
DECLARE names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron'; BEGIN DBMS_OUTPUT.PUT_LINE( REGEXP_SUBSTR(names, '.*,') ); END;
Результат выглядит так:
Anna,Matt,Joe,Nathan,Andrew,Jeff,
Совсем не то. Что произошло? Дело в «жадности» регулярных выражений: для каждого элемента регулярного выражения подыскивается максимальное совпадение, состоящее из как можно большего количества символов. Когда мы с вами видим конструкцию:
.*,
у нас появляется естественное желание остановиться у первой запятой и вернуть строку «,». Однако база данных пытается найти самую длинную серию символов, завершающуюся запятой; база данных останавливается не на первой запятой, а на последней.
В версии Oracle Database 10g Release 1, в которой впервые была представлена поддержка регулярных выражений, возможности решения проблем максимализма были весьма ограничены. Иногда проблему удавалось решить изменением формулировки регулярного выражения — например, для выделения первого имени с завершающей запятой можно использовать выражение . Однако в других ситуациях приходилось менять весь подход к решению, часто вплоть до применения совершенно других функций.
Начиная с Oracle Database 10g Release 2, проблема максимализма отчасти упростилась с введением минимальных квантификаторов (по образцу тех, которые поддерживаются в ). Добавляя вопросительный знак к квантификатору после точки, то есть превращая * в я ищу самую короткую последовательность символов перед запятой:
DECLARE names VARCHAR2(60) := 'Anna,Matt,Joe,Nathan,Andrew,Jeff,Aaron'; BEGIN DBMS_OUTPUT.PUT_LINE( REGEXP_SUBSTR(names, '(.*?,)') ); END;
Теперь результат выглядит так, как и ожидалось:
Anna,
Минимальные квантификаторы останавливаются на первом подходящем совпадении, не пытаясь захватить как можно больше символов.
Unicode категории (category)¶
В стандарте Unicode есть именованные категории символов (Unicode category). Категория обозначается одной буквой, и еще одна добавляется, чтобы указать подкатегорию. Например «L» это буква в любом регистре, «Lu» — буквы в верхнем регистре, «Ll» — в нижнем.
- Cc — Control
- Cf — Формат
- Co — Частное использование
- Cs — Заменитель (Surrrogate)
- Ll — Буква нижнего регистра
- Lm — Буква-модификатор
- Lo — Прочие буквы
- Lt — Titlecase Letter
- Lu — Буква в верхнем регистре
- Mc — Разделитель
- Me — Закрывающий знак (Enclosing Mark)
- Mn — Несамостоятельный символ, как умляут над буквой (Nonspacing Mark)
- Nd — Десятичная цифра
- Nl — Буквенная цифра — например, китайская, римская, руническая и т.д. (Letter Number)
- No — Другие цифры
- Pc — Connector Punctuation
- Pd — Dash Punctuation
- Pe — Close Punctuation
- Pf — Final Punctuation
- Pi — Initial Punctuation
- Po — Other Punctuation
- Ps — Open Punctuation
- Sc — Currency Symbol
- Sk — Modifier Symbol
- Sm — Математический символ
- So — Прочие символы
- Zl — Разделитель строк
- Zp — Разделитель параграфов
- Zs — Space Separator
Метасимвол это один символ указанной Unicode категории (category). Синтаксис: или если категория обозначается одним символом, для 2-символьных категорий.
Метасимвол это символ не из Unicode категории (category).
Литература
- Фридл, Дж. Регулярные выражения = Mastering Regular Expressions. — СПб.: «Питер», 2001. — 352 с. — (Библиотека программиста). — ISBN 5-318-00056-8.
- Смит, Билл. Методы и алгоритмы вычислений на строках (regexp) = Computing Patterns in Strings. — М.: «Вильямс», 2006. — 496 с. — ISBN 0-201-39839-7.
- Форта, Бен. Освой самостоятельно регулярные выражения. 10 минут на урок = Sams Teach Yourself Regular Expressions in 10 Minutes. — М.: «Вильямс», 2005. — 184 с. — ISBN 5-8459-0713-6.
- Ян Гойвертс, Стивен Левитан. Регулярные выражения. Сборник рецептов = Regular Expressions: Cookbook. — СПб.: «Символ-Плюс», 2010. — 608 с. — ISBN 978-5-93286-181-3.
- Мельников С. В. Perl для профессиональных программистов. Регулярные выражения. — М.: «Бином», 2007. — 190 с. — (Основы информационных технологий). — ISBN 978-5-94774-797-3.
- Майкл Фицджеральд. Регулярные выражения. Основы. — М.: «Вильямс», 2015. — 144 с. — ISBN 978-5-8459-1953-3.
Поиск совпадений: метод exec
Метод возвращает массив и ставит свойства регулярного выражения.
Если совпадений нет, то возвращается null.
Например,
// Найти одну d, за которой следует 1 или более b, за которыми одна d
// Запомнить найденные b и следующую за ними d
// Регистронезависимый поиск
var myRe = /d(b+)(d)/ig;
var myArray = myRe.exec("cdbBdbsbz");
В результате выполнения скрипта будут такие результаты:
| Объект | Свойство/Индекс | Описания | Пример |
| Содержимое . | |||
| Индекс совпадения (от 0) | |||
| Исходная строка. | |||
| Последние совпавшие символы | |||
| Совпадения во вложенных скобках, если есть. Число вложенных скобок не ограничено. | |||
| Индекс, с которого начинать следующий поиск. | |||
| Показывает, что был включен регистронезависимый поиск, флаг «». | |||
| Показывает, что был включен флаг «» поиска совпадений. | |||
| Показывает, был ли включен флаг многострочного поиска «». | |||
| Текст паттерна. |
Если в регулярном выражении включен флаг «», Вы можете вызывать метод много раз для поиска последовательных совпадений в той же строке. Когда Вы это делаете, поиск начинается на подстроке , с индекса . Например, вот такой скрипт:
var myRe = /ab*/g;
var str = "abbcdefabh";
while ((myArray = myRe.exec(str)) != null) {
var msg = "Found " + myArray + ". ";
msg += "Next match starts at " + myRe.lastIndex;
print(msg);
}
Этот скрипт выведет следующий текст:
Found abb. Next match starts at 3 Found ab. Next match starts at 9
В следующем примере функция выполняет поиск по input. Затем делается цикл по массиву, чтобы посмотреть, есть ли другие имена.
Предполагается, что все зарегистрированные имена находятся в массиве А:
var A = ;
function lookup(input)
{
var firstName = /\w+/i.exec(input);
if (!firstName)
{
print(input + " isn't a name!");
return;
}
var count = 0;
for (var i = 0; i < A.length; i++)
{
if (firstName.toLowerCase() == A.toLowerCase())
count++;
}
var midstring = (count == 1) ? " other has " : " others have ";
print("Thanks, " + count + midstring + "the same name!")
}
2 Практический раздел. Ссылки
Перед тем, как использовать регулярные выражения, стоит посмотреть в документацию по вашему языку программирования и используемой библиотеке, так как диалекты обладают особенностями. Например в Perl и некоторых версиях php можно описывать рекурсивные регулярные выражения, которые не поддерживаются большинством других реализаций; механизмом флагов отличается JavaScript и так далее. Незначительными отличиями могут обладать даже различные версии одной и той же библиотеки.
Отличаются регулярные выражения не только синтаксисом, но и реализацией. Регулярные выражения — это «не просто так». Строка, задающее выражение, преобразуется в автомат, от реализации которого зависит эффективность. Масштаб проблемы хорошо иллюстрирует график зависимости времени выполнения поиска от длины строки и реализации:
Картинка взята из статьи «Поиск с помощью регулярных выражений может быть простым и быстрым«. В ней можно прочитать про различные реализации выражений, а также о том, как написать выражение так, чтобы оно работало быстрее. Кстати, так как выражение преобразуется в автомат, то зачастую его удобно визуализировать — для этого есть специальные сервисы, например. Для последнего выражения статьи будет построен такой автомат:
Примеры использования регулярных выражений:
- для валидации вводимых в поля данных: QValidator примеры использования. Ряд библиотек построения графического пользовательского интерфейса позволяют закреплять к полям ввода валидаторы, которые не позволяет ввести в формы некорректные данные. По приведенной выше ссылке можно найти валидацию номера банковской карты и номера телефона с помощью регулярных выражений библиотеки Qt. Аналогичные механизмы есть в других языках, например в Java для этого используется пакет ;
- для парсинга сайтов: Парсер сайта на Qt, использование QRegExp. В примере с сайта-галереи выбираются и скачиваются картинки заданных категорий;
- для валидации данных, передаваемых в формате JSON ряд библиотек позволяет задавать схему. При этом для строковых полей могут быть заданы регулярные выражения. В качестве упражнения можно попробовать составить выражение для пароля — проверить что строка содержит символы в разном регистре и цифры.
В сообществе Программирование и алгоритмы можно посмотреть дополнительную литературу по теме. Книгу Гойвертса и Левитана рекомендую посмотреть особенно, так как в ней по-полочкам разобраны десятки примеров, причем с учетом специфики реализации регулярных выражений в конкретных языках программирования.








