Узнайте как выглядел сайт в прошлом. и о том, как изменялись популярные сайты за 20 лет
Содержание:
- Как посмотреть, как раньше выглядела страница «ВКонтакте» через поиск Google?
- Кэш браузера
- А теперь подробно
- Статьи
- Что такое веб-архив и зачем он нужен?
- Кто такой Тим Бернерс Ли
- Поиск сайтов в Wayback Machine
- Почему страницы может не быть?
- 7 методов проверки истории
- Как посмотреть сайт в прошлом — Как посмотреть страницу в ВК
- Скопировать из браузера
- JS Examples
- Как использовать веб-архив?
- Как посмотреть удаленную страницу в веб-архиве
- Всемирный Веб архив сайтов интернета
- Индексация веб-страниц в интернете
- Просмотр копии страницы в поисковиках
- История архива Интернета
- Уникальный контент из «мертвых» сайтов
- web.archive.org
Как посмотреть, как раньше выглядела страница «ВКонтакте» через поиск Google?
В данной статье мы рассмотрим способы просмотра старых копий страниц, но здесь нужно отметить, что таким способом можно посмотреть только профили тех людей, что не были скрыты настройками приватности, которые закрывают страницу от поисковых систем. При этом здесь можно посмотреть даже те страницы, что ранее были удалены.
Сначала мы расскажем о том, как посмотреть старую версию страницы, пользуясь популярным поисковиком Google, который умеет сохранять различные страницы в Интернете в их ранних версиях. Но здесь нужно понимать, что все эти сохраненные страницы остаются в памяти поисковика на ограниченный период времени, то есть старая версия удаляется после того, как она будет сканирована снова.
В поисковой строке нужно ввести запрос с именем человека «ВКонтакте», а также со специальным добавлением site:vk.com, чтобы Google показывал результаты только внутри этой социальной сети. В поисковой выдаче далее нужно найти требуемую страницу и рядом с нею нажать на кнопку с зеленым треугольником, чтобы открыть меню с дополнительными функциями. Далее в отобразившемся списке нужно выбрать пункт «Сохраненная копия».
После этого пользователь попадет на страницу искомого человека, причем на ту ее версию, что сканировалась поисковиком Google в предыдущий раз. В зависимости от того, насколько старая версия в итоге откроется, может изменяться даже сам интерфейс социальной сети «ВКонтакте».
Также стоит отметить, что даже если пользователь уже авторизовался в этой социальной сети, он увидит данную страницу со стороны человека, которые не зарегистрирован «ВКонтакте», то есть как анонимный посетитель, потому что именно так видят профили на данном сайте роботы Google. Если же пользователь решит зайти в свой профиль, чтобы подробнее просмотреть материалы, размещенные на сохраненной версии найденной страницы, он просто попадет на оригинальную текущую версию «ВКонтакте». Это значит, что таким способом можно посмотреть только ту основную информацию, что была размещена непосредственно на самой странице человека, а все остальные дополнительные материалы просто не получится открыть. Именно поэтому здесь нельзя будет, например, просмотреть список подписчиков или все фотографии человека. Также стоит заметить, что смотреть старые сохраненные версии профилей известных и популярных людей в этой социальной сети, по сути, не имеет никакого смысла, потому что на эти страницы заходит слишком много людей, а потому они намного чаще сканируются поисковыми системами.
Кэш браузера
Если ни один из представленных ваше способов не помог вам найти нужную страницу, остается надеяться только на то, что копия уже сохранена на вашем компьютере. Большинство современных браузеров сохраняет информацию посещенных сайтов. Это необходимо для ускорения загрузки. Попробуйте открыть необходимую страницу в автономном режиме.
В браузере Mozilla Firefox это делается следующим образом:
- зайдите в меню, нажав кнопку в виде трех горизонтальных полос;
- выберите пункт «Веб-разработка»;
в этом подменю нажмите «Работать автономно».
Когда вы перешли в автономный режим, браузер не сможет загружать никакую информацию из интернета. Он будет использовать только те данные, которые сохранил на компьютере. Введите в адресную строку адрес нужной вам страницы и нажмите «Enter». Если на компьютере есть сохраненная версия аккаунта, то браузер загрузит его. В противном случае он скажет, что страница не найдена и напомнит вам, что он работает в автономном режиме.
Как видите, даже из самых, казалось бы, безвыходных ситуаций можно найти выход. Если же ни один из способов вам не помог, то позвоните другу и попросите восстановить страницу. А также отправьте ему ссылку на сайт vkbaron.ru, чтобы он видел, сколько всего интересного можно делать в социальной сети Вконтакте. В случае если вы пытаетесь сохранить информацию со своей страницы, которую кому-то удалось взломать, обязательно ознакомьтесь со статьей о составлении пароля, который не сможет подобрать ни один хакер.
А теперь подробно
1. Выделяем текст или его часть.
Подводим курсор (палочку) в самое начало текста, который нужно скопировать. Затем нажимаем на левую кнопку мышки и, не отпуская ее, как будто бы обводим строки. Когда они закрасятся каким-нибудь цветом (скорее всего, голубым), отпускаем кнопку мышки. Выделение при этом должно остаться.
2. Копируем то, что выделили.
Наводим курсор в любое место закрашенной части и нажимаем правую кнопку мышки. Появится список. При этом выделение должно остаться. В списке наводим на пункт «Копировать» и щелкаем по нему левой кнопкой мышки.
3. Открываем программу для вставки текста.
Это может быть Microsoft Word, WordPad, Блокнот или какая-то другая. Для ее открытия щелкаем по кнопке «Пуск» в нижнем левом углу экрана и из списка выбираем «Все программы».
Далее ищем пункт Microsoft Office и там выбираем Microsoft Office Word.
Если ничего подобного вы у себя не находите, откройте пункт «Стандартные» и выберите программу «WordPad» или «Блокнот».
4. Вставляем информацию в программу.
Когда программа откроется, нажимаем внутри нее, то есть по белой части, правой кнопкой мышки. Появится список, из которого выбираем пункт «Вставить».
Если все сделано правильно, то текст из интернета вставится в программу.
Картинки и фотографии обычно добавляются вместе с ним.
5. Сохраняем на компьютер.
Хоть информация и вставилась, но на компьютер она еще не записана. Чтобы это сделать, нужно нажать на кнопку «Файл» в приложении и выбрать «Сохранить» или «Сохранить как…».
Появится окошко, в котором нужно выбрать место в компьютере, куда следует записать данные.
Например, я хочу сохранить документ в Локальный диск D. Значит, выбираю диск D в этом окошке.
А если я хочу записать его сразу на флешку, то выбираю именно ее в этом окошке.
Кстати, прямо здесь, внутри, можно создать отдельную папку для текста.
После того как в окошке выбрано нужное место, обратите внимание на поле «Имя файла». В нем указано то название, которое система предлагает дать документу
Если оно не подходит, можно напечатать другое, более подходящее.
Когда место для файла выбрано и имя назначено, нажимаем кнопку «Сохранить».
Теперь полностью закрываем приложение и открываем то место на ПК, которое выбирали в окошке сохранения.
В моем случае это был Локальный диск D. Значит, открываю Пуск – Компьютер и захожу в диск D.
Там должен быть файл, открыв который, появится тот самый текст из интернета.
Как очистить текст от мусора
Зачастую скопированный текст добавляется в программу вместе с оформлением, какое было у него в интернете. Бывает, оно выглядит не очень симпатично.
Поправить это легко: нужно просто выделить текст (так же, как мы это делали при копировании) и нажать на вот такую кнопку вверху программы Word — она находится в закладке «Главная».
Сразу после этого у выделенных данных уберутся все эффекты.
P.S.
Это краткая инструкция по записи текста из интернета в компьютер. Если вы в чем-то не до конца разобрались, советую изучить подробную инструкцию вот по этой ссылке.
Статьи
Что такое веб-архив и зачем он нужен?
Веб-архив — история миллионов сайтов
Веб-архив — это специализированный сайт, который предназначен для сбора информации о различных интернет-ресурсах. Робот осуществляет сохранение копии проектов в автоматическом и ручном режиме, все зависит лишь от площадки и системы сбора данных.
На текущий момент имеется несколько десятков сайтов со схожей механикой и задачами. Некоторые из них считаются частными, другие — открытыми для общественности некоммерческими проектами. Также ресурсы отличаются друг от друга частотой посещения, полнотой сохраняемой информации и возможностями использования полученной истории.
Как отмечают некоторые эксперты, страницы хранения информационных потоков считаются важной составляющей Web 2.0. То есть, частью идеологии развития сети интернет, которая находится в постоянной эволюции
Механика сбора весьма посредственная, но более продвинутых способов или аналогов не имеется. С использованием веб-архива можно решить несколько проблем: отслеживание информации во времени, восстановление утраченного сайта, поиск информации.
Кто такой Тим Бернерс Ли
У Бернерса Ли идеальный образ значимой фигуры в IT-индустрии.
Он знаком с технологиями с детства. Его родители были математиками и занимались разработкой одного из первых компьютеров в мире «Марк I».
Учась в Оксфордском королевском колледже, Тим устроил хакерскую атаку на учебное заведение. За это ему запретили пользоваться университетскими десктопами.
Ломал сетку, до того как это стало мэйнстримом.
С начала запуска Веба британец настаивал, что интернет должен быть общедоступным и децентрализованным.
Он даже не попытался заработать на правах на технологию и отказался патентовать ее.
«Если бы эта технология была проприетарной, и я полностью ее контролировал, она бы, скорее всего, не взлетела. Невозможно предложить то, что было бы общедоступным, и при этом вы сохранили контроль над ним», — говорил ученый.
Тим Бернерс Ли слева, Роберт Кайо справа
Помимо причастности к созданию первого сайта, Тим Бернерс Ли считается изобретателем URI, URL, HTTP и HTML. Именно эти технологии можно найти в info.cern.ch.
Если точнее, Бернерс Ли придумал:
язык разметки HTML для создания веб-страниц
протокол HTTP для передачи данных в Вебе
систему унифицированных адресов ресурсов URL для поиска документа или страницы
Эти технологии применяются в интернете и сейчас.
Поиск сайтов в Wayback Machine
Wayback Machine
На странице «Internet Archive Wayback Machine» введите в поле поиска URL адрес сайта, а затем нажмите на кнопку «BROWSE HISTORY».
Под полем поиска находится информация об общем количестве созданных архивов для данного сайта за определенный период времени. На шкале времени по годам отображено количество сделанных архивов сайта (снимков сайта может быть много, или, наоборот, мало).
Выделите год, в центральной части страницы находится календарь, в котором выделены голубым цветом даты, когда создавались архивы сайта. Далее нажмите на нужную дату.
Вам также может быть интересно:
- Советские фильмы онлайн в интернете
- Яндекс Дзен — лента персональных рекомендаций
Обратите внимание на то, что при подведении курсора мыши отобразится время создания снимка. Если снимков несколько, вы можете открыть любой из архивов
Сайт будет открыт в том состоянии, которое у него было на момент создания архива.
За время существования моего сайта, у него было только два шаблона (темы оформления). На этом изображении вы можете увидеть, как выглядел мой сайт в первой теме оформления.
На этом изображении вы видите сайт моего знакомого, Алема из Казахстана. Данного сайта уже давно нет в интернете, поисковые системы не обнаруживают этот сайт, но благодаря архиву интернета все желающие могут получить доступ к содержимому удаленного сайта.
Почему страницы может не быть?
Иногда во время поиска при нажатии на стрелочку сниппета нужного пункта может и не быть. Это происходит по ряду причин:
- Сбой в работе поисковика. В Яндексе даже не скрывают, что нет никаких гарантий на наличие и показ копий — система может просто не сохранять страницы по какой-либо причине.
- Второй вариант: html-кодировка документа содержит мета-тег «robots» со значением «noarchive», что означает запрет на кэширование. Чтобы не рисковать из-за этого трафиком, стоит внимательно настроить соответствующие блоки и очистить ненужные значения.
Нет копии: чем это грозит?
С точки зрения продвижения — опасность нулевая. А вот сами причины, из-за которых невозможно сохранение, могут быть вредны, нужно разбираться именно в них.
Эксперты уверены, что проблема с копиями может обернуться трудностями при работе с биржами ссылок. Так, на некоторых известных биржах строго контролируют, есть ли в Яндексе копия, проверяя параметр No Index Cache (NIC).
7 методов проверки истории
Reg.ru (платный способ)
Первый способ, которым вы можете воспользоваться, — это специальный инструмент проверки истории у официального регистратора REG.RU.
Перейдя по прямой ссылке: reg.ru/whois/history. Регистрируетесь, пополняете баланс на нужную сумму и запрашиваете данную проверку.
Все адреса во время поиска и выбора подходящего, конечно, проверять будет дороговато. Поэтому им лучше пользоваться в случае, если вы уже конкретно определились с каким-то свободным вариантом.
Все последующие способы бесплатные.
Whoishistory.ru
Whoishistory.ru — стандартный сервис для просмотра общедоступной информации о домене. Работает только с доменными зонами .ru, .su, .рф.
Необязательно пользоваться расширенным функционалом, сколько не пробовал, особо важных данных он не показывает. Просто вводите адрес в зелёном поле и нажимаете “Найти”.
Далее открывается окно с данными.
Показываются отдельно данные за каждый год, в моём случае — за 3 года:
- Сервера хостинга, где расположен.
- Статус доступности.
- Кем зарегистрирован. Если на физическое лицо, как в моём случае, то конкретно на кого — не показывается.
- У какого регистратора он приобретён.
- Дата регистрации (возраст).
- Даты, когда он продлевался.
По этим данным самое главное, что можно увидеть, — был он ранее кем-то занят или нет и как давно занят.
Если увидите, что он уже использовался, анализируем следующими сервисами.
Linkpad.ru
Можно таким образом определить тематику бывшего ресурса и качество ссылок.
В моём случае домен абсолютно новый и все данные за последние 5 лет по нулям. Вот пример занятого домена, сайт на котором уже не работает, выставлен на продажу и, который я хотел купить.
Можно ещё увидеть, какие страницы недавно были на сайте.
Ничего страшного в таком домене нет, можно считать, что история нормальная. Вот только цену за него предложили 28 000 рублей. А моим принципам противоречит покупать доменные имена у киберсквоттеров.
Screenshots.com
Screenshots.com — сервис, делающий скриншоты сайтов и сохраняющий их в истории. Минус его в том, что он делает скрины только популярных сайтов.
Разные мелкие ресурсы, которые находились на домене недолго, он не показывает. С этой задачей лучше справляется следующий сервис.
Archive.org
Archive.org — всемирный архив интернета, периодично сохраняет вид сайтов на протяжении всей его работы. Можно посмотреть, как выглядели популярные интернет-гиганты ранее и менялись с момента создания.
В шкале сверху показываются все года и количество сохранений. А в календаре — обведённые и выделенные жирным цифры, когда был сохранён архив. При нажатии на них вы можете его посмотреть. Так выглядел мой блог, когда я его только запустил в 2014 году.
Данными крайними двумя способами можно определить, что за сайт находился на домене, и нарушал ли он какие-либо нормы интернета.
Проверка в поиске
Не помешает также спросить Яндекс и Гугл, что они помнят о бывшем веб-сайте, расположенном на выбранном вами домене. Для этого в поисковой строке вбиваете доменное имя полностью и смотрите результаты.
Если обнести домен в кавычки и поставить перед словом знак восклицания (рекомендую почитать статью про секреты поиска), то Яндекс покажет только прямые вхождения того слова, которое вы ищете.
Нашлось 12 тыс. страниц, где упоминается мой домен. По данному анализу можно понять, что за ресурсы ссылаются на доменное имя, и определить хороший или плохой был расположенный на нём материал.
RDS bar
RDS bar — это расширение для браузера, помогающее вебмастерам быстро получить доступную информацию о сайте. Даже если сайт по нужному доменному имени не открывается, он всё равно покажет статистику.
Для этого устанавливаете расширение. В браузерной строке вводите нужный адрес и пытаетесь его открыть. Когда выдаст ошибку о недоступности, нажимаете на значок.
Если цифры не по нулям, то значит он использовался ранее и индексировался. Нажимая на цифры, увидите подробные данные.
Как посмотреть сайт в прошлом — Как посмотреть страницу в ВК
«Сайт, который возвращает в прошлое сайтов» мы уже упоминали в статьях Как попасть в глубокий интернет, The Wayback Machine и Как найти заброшенные сайты. Однако в тех статьях рассказывалось о том, как искать уже не существующие, «мертвые» web-ресурсы, о которых вы узнали уже тогда, когда они прекратили свою жизнь.
В этой статье мы разберем, как посмотреть, как выглядел сайт в прошлом, который и в настоящее время остается живым и присутствует в сети Интернет, а также ответим на вопрос, как посмотреть страницу ВКонтакте в прошлом. Для этого мы воспользуемся уже упомянутым ресурсом The Wayback Machine или web.archive.org, который хранит в себе множество копий каждого найденного их роботами сайта. Более популярные web-ресурсы фиксируются чаще, малоизвестные – реже, о небольших сателлитах The Wayback Machine может даже не «знать».
Чем более обновляемым и посещаемым является портал, тем чаще на него заходят роботы Web-архива. Так, посмотреть, как выглядел yandex.ru, можно аж с 1998 года:
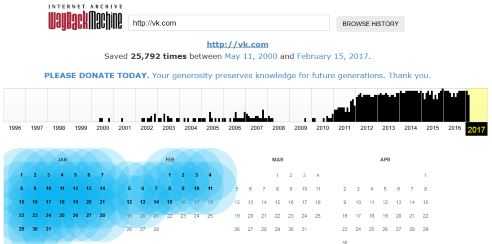
А историю сайта, расположенного на домене vk.com, – с 2000 года (кстати, владельцы социальной сети ВКонтакте приобрели это доменное имя только в 2009):

Чтобы узнать, как выглядел интересующий вас сайт в определенном году, необходимо выбрать в верхней шкале интересующий вас период и кликнуть по любой отмеченной голубым цветом дате. Это позволит проанализировать то, как видоизменялся web-ресурс на протяжении своего существования.
Веб-архив позволяет посмотреть не только прошлые версии сайтов, но и их отдельные документы, например, страницу в ВК. Однако боты The Wayback Machine кэшируют страницы ВКонтакте в том виде, в каком они показываются незарегистрированным пользователям, поэтому большая часть информации будет не сохранена. Кроме того, в web.archive.org имеются сведения далеко не обо всех профилях ВКонтакте, так как на данный момент социальная сеть настолько огромна, что роботы The Wayback Machine просто не успевают обойти ее всю.
Как посмотреть страницу в ВК в прошлом
Чтобы посмотреть страницу в ВК в прошлом при помощи Веб-архива, вбейте в поисковую строку сайта интересующий вас адрес в формате vk.com/id1 или vkontakte.ru/id1, заменив цифру 1 на интересующий вас ID, и нажмите кнопку Browse History.
Однако если пользователь ВК изначально запретил просмотр своего профиля поисковыми системами (сделать это можно в разделе Настройки – Приватность – Прочее),
в Веб-архиве сохранится только документ, расположенный по адресу http://vkontakte.ru/login.php?u=1.
Скопировать из браузера
Можно перенести данные из обозревателя в любой текстовый редактор. Для этого лучше всего подойдёт Microsoft Word. В нём корректно отображаются изображения и форматирование. Хотя из-за специфики документа может не очень эстетично выглядеть реклама, меню и некоторые фреймы.
Вот как скопировать страницу сайта:
- Откройте нужный URL.
- Нажмите Ctrl+A. Или кликните правой кнопкой мыши по любой свободной от картинок и flash-анимации области и в контекстном меню выберите «Выделить». Это надо сделать для охвата всей информации, а не какого-то произвольного куска статьи.
- Ctrl+C. Или в том же контекстном меню найдите опцию «Копировать».
- Откройте Word.
- Поставьте курсор в документ и нажмите клавиши Ctrl+V.
- После этого надо сохранить файл.
Иногда получается так, что переносится только текст. Если вам нужен остальной контент, можно взять и его. Вот как скопировать страницу веб-ресурса полностью — со всеми гиперссылками, рисунками:
- Проделайте предыдущие шаги до пункта 4.
- Кликните в документе правой кнопкой мыши.
- В разделе «Параметры вставки» отыщите кнопку «Сохранить исходное форматирование». Наведите на неё — во всплывающей подсказке появится название. Если у вас компьютер с Office 2007, возможность выбрать этот параметр появляется только после вставки — рядом с добавленным фрагментом отобразится соответствующая пиктограмма.
Способ №1: копипаст
В некоторых случаях нельзя скопировать графику и форматирование. Только текст. Даже без разделения на абзацы. Но можно сделать скриншот или использовать специальное программное обеспечение для переноса содержимого страницы на компьютер.
Сайты с защитой от копирования
Иногда на ресурсе стоит так называемая «Защита от копирования». Она заключается в том, что текст на них нельзя выделить или перенести в другое место. Но это ограничение можно обойти. Вот как это сделать:
- Щёлкните правой кнопкой мыши в любом свободном месте страницы.
- Выберите «Исходный код» или «Просмотр кода».
- Откроется окно, в котором вся информация находится в html-тегах.
- Чтобы найти нужный кусок текста, нажмите Ctrl+F и в появившемся поле введите часть слова или предложения. Будет показан искомый отрывок, который можно выделять и копировать.
Если вы хотите сохранить на компьютер какой-то сайт целиком, не надо полностью удалять теги, чтобы осталась только полезная информация. Можете воспользоваться любым html-редактором. Подойдёт, например, FrontPage. Разбираться в веб-дизайне не требуется.
- Выделите весь html-код.
- Откройте редактор веб-страниц.
- Скопируйте туда этот код.
- Перейдите в режим просмотра, чтобы увидеть, как будет выглядеть копия.
- Перейдите в Файл — Сохранить как. Выберите тип файла (лучше оставить по умолчанию HTML), укажите путь к папке, где он будет находиться, и подтвердите действие. Он сохранится на электронную вычислительную машину.
Защита от копирования может быть привязана к какому-то js-скрипту. Чтобы отключить её, надо в браузере запретить выполнение JavaScript. Это можно сделать в настройках веб-обозревателя. Но из-за этого иногда сбиваются параметры всей страницы. Она будет отображаться неправильно или выдавать ошибку. Ведь там работает много различных скриптов, а не один, блокирующий выделение.
Если на сервисе есть подобная защита, лучше разобраться, как скопировать страницу ресурса глобальной сети другим способом. Например, можно создать скриншот.
JS Examples
Как использовать веб-архив?
Форма для поиска информации на Peeep.us
Как уже отмечалось выше, веб-архив — это сайт, который предоставляет определенного рода услуги по поиску в истории. Чтобы использовать проект, необходимо:
- Зайти на специализированный ресурс (к примеру, web.archive.org).
- В специальное поле внести информацию к поиску. Это может быть доменное имя или ключевое слово.
- Получить соответствующие результаты. Это будет один или несколько сайтов, к каждому из которых имеется фиксированная дата обхода.
- Нажатием по дате перейти на соответствующий ресурс и использовать информацию в личных целях.
О специализированных сайтах для поиска исторического фиксирования проектов поговорим далее, поэтому оставайтесь с нами.
Как посмотреть удаленную страницу в веб-архиве
Веб-архив – это специальный сервис, который хранит на своем сервере данные со всех страниц, которые есть в интернете. Даже, если сайт перестанет существовать, то его копия все равно останется жить в этом хранилище.
В архиве также хранятся все версии интернет страниц. С помощью календаря разрешено смотреть, как выглядел тот или иной сайт в разное время.
В веб-архиве можно найти и удаленные страницы с ВК. Для этого необходимо выполнить следующие действия.
- Зайти на сайт https://archive.org/.
- В верхнем блоке поиска ввести адрес страницы, которая вам нужна. Скопировать его из адресной строки браузера, зайдя на удаленный аккаунт ВК.
Используя интернет-архив вы, естественно, не сможете написать сообщение, также как узнать когда пользователь был в сети. Но посмотреть его последние добавленные записи и фото очень даже можно.
Страница найдена
Если искомая страница сохранена на сервере веб-архива, то он выдаст вам результат в виде календарного графика. На нем будут отмечены дни, в которые вносились изменения, добавлялась или удалялась информация с профиля ВК.
Выберите дату, которая вам необходима, чтобы увидеть, как выглядела страница. Используйте стрелочки «вперед» и «назад», чтобы смотреть следующий или предыдущий день либо вернитесь на первую страницу поиска и выберите подходящее число в календаре.
Страница не найдена
Может случиться, что необходимая страница не нашлась на сайте WayBackMachine. Это не значит, что вы что-то сделали не правильно, такое часто случается. Возможно, аккаунт пользователя был закрыт от поисковиков и посторонних сайтов и поэтому не попал в архив. WayBackMachine самый популярный сайт, но он не единственный в своем роде. Попробуйте найти в Яндексе или Гугле другие веб-архиви. Искомая страница могла сохраниться на их серверах.
Попытайте удачу в поисках архивной версии профиля на этих сайтах:
- archive.is;
- webcitation.org;
- freezepage.com;
- perma.cc.
Также обязательно попробуйте найти страничку на русскоязычном аналоге http://web-arhive.ru/.
Всемирный Веб архив сайтов интернета
Хранилище интернет-архив конечно не содержит всех страниц, которые когда-либо были созданы. Но шанс найти интересующий вас сайт и его архивную копию достаточно велик.
Самый мощный архив веб-сайтов доступен на Archive.org по адресу www.archive.org. Он индексирует веб, виде-, аудио и текстовые материалы, которые доступны в интернете.
Запустите ваш любимый веб-браузер и введите www.archive.org в адресной строке . Через некоторое время вы увидите главную страницу сайта интернет-архива. Она разделена на несколько частей. Каждая часть позволяет искать различный тип контента.
Раздел видео, содержит на момент написания статьи более 830 тысяч фильмов.
Раздел аудио, включает в себя более 2 миллионов записей, при это доступен еще раздел живой музыки, который насчитывает около 200 тысяч прямых трансляций с концертов в Интернет.
Однако наиболее интересным и значимым разделом сайта Archive.org является раздел web-страницы. На сегодняшний день он позволяет получить доступ к более чем 349 миллиардам архивных веб-сайтов. Для данного раздела даже выделен отдельный поддомен web.
Главная страница сайта Archive.org
Индексация веб-страниц в интернете
Начиная с 1996 года по настоящее время на сайте archive.org собрано более 466 миллиардов веб-страниц (эта цифра все время увеличивается). Архив страниц интернета создан для сохранения, ознакомления и изучения имеющей информации, которая накопилась за все эти годы во всемирной сети.
Время от времени, специальные роботы, принадлежащие сервису, индексируют содержание практически всех сайтов в интернете
Следует принять во внимание, что во время обхода робота для индексации сайтов, на некоторых сайтах могли возникать внутренние проблемы: сайт, или некоторые страницы сайта были недоступны, сайт находился на техобслуживании, не работали подключаемые внешние элементы и т. д
Поэтому некоторые архивы сайтов будут полными, а некоторые снимки (архивы) могут содержать только частичную информацию. Имейте в виду, что некоторые сайты индексируются часто, другие сайты, наоборот, довольно редко.
Для просмотра веб-страниц используется онлайн сервис The Wayback Machine. В Internet Archive доступны для просмотра не только действующие в настоящий момент сайты, но и сайты, которые уже не существуют. С помощью архива интернета можно побывать на прекративших существование сайтах, и ознакомится с содержимым веб-страниц удаленных сайтов.
Благодаря замечательному архиву сайтов интернета можно проследить историю изменений, как изменялся внешний облик сайта и его содержимое с течением времени, использовать архивы для восстановления сайта, искать необходимую информацию.
На главной странице сайта archive.org можно получить доступ к архивным данным, которые сгруппированы в тематические разделы, или сразу перейти на страницу сервиса Wayback Machine.
Просмотр копии страницы в поисковиках
Зная алгоритмы работы поисковых роботов, можно использовать их возможности в своих целях. Каждый созданный сайт, попадает в Яндекс и Гугл не сразу. Он размещается на специальном сервере и ждет, пока поисковик найдет его и добавит в свою базу. Такие обходы поисковые системы выполняют в среднем один раз в 14 дней. Во время этого процесса они не только добавляют в свою базу новые сайты, но удаляют неработающие. Это значит, что если страничка ВКонтакте была удалена совсем недавно, то возможно ее копия еще сохранилась на серверах поисковиков.
- Скопируйте адрес страницы, которую нужно найти, из адресной строки браузера.
- Вставьте эту ссылку в поисковую строку Яндекса или Гугла и нажмите «Поиск».
- Если страница все еще храниться в поисковике, то она будет первой в результатах выдачи. Справа от ссылки находится еле заметный треугольник. Нажмите на него.
- В открывшемся меню выберите «Сохранённая копия».
Перед вами откроется последняя версия страницы, которую сохранил Яндекс или Гугл. Сохраните фото, видео и всю прочую необходимую информацию себе на компьютер, так как совсем скоро сохраненная копия будет удалена с серверов поисковых машин.
История архива Интернета
Итак, как же выглядел сайт в прошлом, и какие инструменты могут нам помочь заглянуть в веб-историю 5-10 летней давности? Более 20 лет назад, в 1996 году энтузиаст Кейл Брюстер основал цифровой архив под названием «Архив Интернета» («The Internet Archive»), слоганом которого был провозглашён «Всеобщий доступ к знаниям». С того времени указанный архив собирает и хранит копии веб-страниц, графики, аудио и видео, различных программ, обеспечивая свободный доступ к накопленной информации для всех желающих.
На состояние октября 2016 года архив уже имел 15 петабайт информации, а веб-архив проекта содержал уже более 150 миллиардов веб-страниц различных сайтов.

Именно благодаря данному архиву сегодня мы имеем возможность посмотреть, как выглядели многие ресурсы 10-15-20 лет тому назад. Историю действий на вашем компьютере можно узнать в статье написанной мной ранее.
Уникальный контент из «мертвых» сайтов
Каждый день из интернета исчезают десятки и даже сотни разнообразных сайтов. Стоит отметить, что абсолютное большинство не представляет особой ценности, но в каждой реке можно найти много крупинок золота. Главное, чтобы полезные сайты имели хотя бы один работающий слепок в archive.org.
Поскольку информация из умерших сайтов поступенно перестает индексироваться поисковыми системами, такой контент становится уникальным (конечно, если он не был «сплагиачен» до этого). Выставив эту информацию на свой ресурс, вы станете ее правообладателем или первоисточником для поисковых систем. Главное, предварительно проверить ее на уникальность, чтобы не нарушить ничей копирайт. Но как именно отыскать подобные ресурсы среди гор мусора?
К счастью, существует один способ.
После этого нужно всего лишь просматривать информацию Webarchive с каждого ресурса, который вас заинтересовал. Безусловно, такой метод предполагает наличие внимательности, а также терпения, поскольку качество большинства данного контента будет низкопробным.
web.archive.org
В самом верху написано, сколько всего снимком страницы сделано, дата первого и последнего снимка.
Затем идёт шкала времени на которой можно выбрать интересующий год, при выборе года, будет обновляться календарь.
Обратите внимание, что календарь показывает не количество изменений на сайте, а количество раз, когда был сделан архив страницы.
Точки на календаре означают разные события, разные цвета несут разный смысл о веб захвате. Голубой означает, что при архивации страницы от веб-сервера был получен код ответа 2nn (всё хорошо); зелёный означает, что архиватор получил статус 3nn (перенаправление); оранжевый означает, что получен статус 4nn (ошибка на стороне клиента, например, страница не найдена), а красный означает, что при архивации получена ошибка 5nn (проблемы на сервере). Вероятно, чаще всего вас должны интересовать голубые и зелёные точки и ссылки.
Используя эту миниатюру вы сможете переходить к следующему снимку страницы, либо перепрыгнуть к нужной дате:
Кроме календаря доступна следующие страницы:
- Collections — коллекции. Доступны как дополнительные функции для зарегистрированных пользователей и по подписке
- Changes
- Summary
- Site Map
Changes
«Changes» — это инструмент, который вы можете использовать для идентификации и отображения изменений в содержимом заархивированных URL.
Начать вы можете с того, что выберите два различных дня какого-то URL. Для этого кликните на соответствующие точки:
И нажмите кнопку Compare. В результате будут показаны два варианта страницы. Жёлтый цвет показывает удалённый контент, а голубой цвет показывает добавленный контент.
В этой вкладке статистика о количестве изменений MIME-типов.
Site Map
Как следует из название, здесь показывается диаграмма карты сайта, используя которую вы можете перейти к архиву интересующей вас страницы.
Если вместо адреса страницы вы введёте что-то другое, то будет выполнен поиск по архивированным сайтам:
Показ страницы на определённую дату
Кроме использования календаря для перехода к нужной дате, вы можете просмотреть страницу на нужную дату используя ссылку следующего вида: http://web.archive.org/web/ГГГГММДДЧЧММСС/АДРЕС_СТРАНИЦЫ/
Обратите внимание, что в строке ГГГГММДДЧЧММСС можно пропустить любое количество конечных цифр.
Если на нужную дату не найдена архивная копия, то будет показана версия на ближайшую имеющуюся дату.