Как собрать семантическое ядро: пошаговая инструкция
Содержание:
- 3 часто допускаемые ошибки в сборе семантического ядра
- Сервисы составления семантического ядра
- Удаляем слова с нулевой частотностью
- PHP Формы
- Особенности сбора семантики по видам проектов
- Скидка за объем приобретаемого товара
- Принцип составления семантического ядра
- Кластеризация запросов
- Видео: троянский вирус
- Очистка СЯ от «мусора»
- SEO или контекст – что лучше
- Подбор посадочных страниц
- Простое мобильное приложение, информирующее об остатках на складах и ценах по штрихкоду, для 1С: УНФ, Розница, УТ 11
- Семантика для фидов
- 5 типичных ошибок при сборе семантического ядра для сайта
- Задача
3 часто допускаемые ошибки в сборе семантического ядра
Зачастую неопытные пользователи не до конца понимают, как производить сбор семантического ядра, и допускают ошибки. Эти ошибки, конечно, не фатальные, но способны вызвать негативные последствия.
- Контент страницы и запрос не соответствуют друг другу. Пример: вы включили в семантическое ядро запрос («фитнес браслет отзывы»). Но фактически отзывы у вас на странице отсутствуют. Соответственно, человек не найдет необходимые ему сведения. Не нужно намеренно писать об отзывах в тексте. Человек зайдет на сайт и поймет, что его обманули. В результате у него сформируется негативное отношение к вашему ресурсу и компании в целом. Надо сказать, что в рекламных целях такой запрос можно применять к странице, хотя это и нежелательно.
- В семантическое ядро включены запросы с нулевой частотностью. То есть такие запросы «пустые» и пользователи их не ищут. Такого рода запросы не приносят вам трафика. Частотность – первый показатель, который нужно проверять после сбора семантического ядра.
- Ключевые запросы подобраны без ориентира на пользователя. В первую очередь следует понять, что в поисковиках ищет ЦА и что полезного вы вместе со своим сайтом можете ей предложить.
Помните, каждый день рынок пополняется новыми продуктами, интересы и пожелания аудитории меняются, а потому важно оставаться в тренде и своевременно адаптироваться к новым веяниям. Конечно, в повседневной суете не всегда есть время на аналитику
Но разовый сбор семантического ядра без последующей работы в данном направлении – абсолютно бесперспективная идея.
Сервисы составления семантического ядра
Начнем с того, что все сервисы для составления семантического ядра (сервисы подбора ключевых слов) это отдельные услуги в рамках серверов занимающихся комплексным продвижением сайтов. Отдельные проверки у них чаще платные, или становятся платными, если запускать свой проект. Подробно лучше почитать в статье: 17 сервисов подбора ключевых слов.
Сервера продвижения сайтов
На сервисах продвижения сайта, есть услуга или инструмент составления семантического ядра. Среди сервисов продвижения сайтов выделю четыре из них:
- SEOLib (https://seolib.ru),
- Seopult (https://seopult.ru),
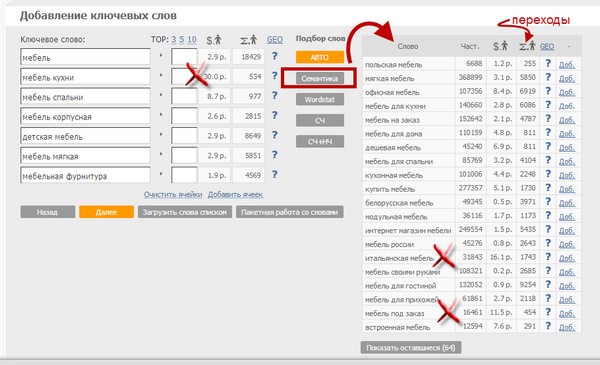
Чтобы воспользоваться сервисом Seopult, нужно:
- Зарегистрироваться через почту;
- Создать тестовый проект;
- Провести исследование по 5 позициям: Авто; Семантика; Wordstat; СЧ; СЧ+НЧ;
 Составление семантического ядра
Составление семантического ядра
- Слева вводите основные ключевые слова ( ВЧ);
- Отметаете ключевики с большой ценой перехода;
- С помощью кнопок управления Авто; Семантика; Wordstat;СЧ; СЧ+НЧ делаете подбор дополнительных ключевых слов;
Webeffector- https://www.webeffector.ru
Этот сервис продвижения тоже платный, но на этапе настройки проекта можно составить семантическое ядро.
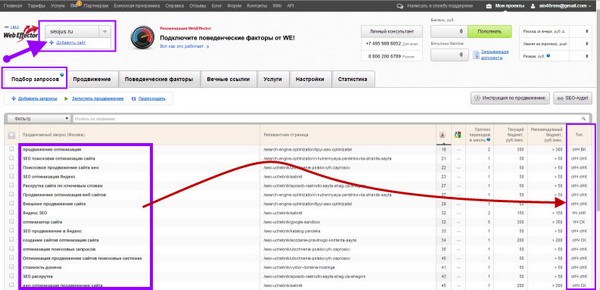 Составление семантического ядра на сервисе продвижения Webeffector
Составление семантического ядра на сервисе продвижения Webeffector
- Нужно зарегистрироваться;
- Добавить сайт;
- Задать задачу;
- И сделать подбор ключевых слов для этой задачи.
Кроме слов для этой задачи, вам покажут еще массу ключевиков, которые вы можете использовать в семантическом ядре. Кстати, здесь сразу можно увидеть результаты по анализу конкурентности запросов.
Третий сервис лучший из перечисленных. Это один из инструментов Megaindex.ru.
Megaindex (http://keywords.megaindex.ru/)
Вот как они пишут о себе сами:
SeoJus.ru
Удаляем слова с нулевой частотностью
Для целей контекстной рекламы слова с околонулевой частотностью не представляют интереса, поскольку по ним не будет показов. Такие слова лучше сразу удалить.
Для проверки частотности большого массива ключей в Click.ru есть парсер Wordstat. Он собирает частотности из левой колонки Wordstat. Он парсит частотность в любом регионе Яндекса и учитывает тип соответствия ключевых слов.
Как пользоваться инструментом
Перейдите на страницу инструмента. Добавьте запросы.
Выберите регион, по которому инструмент будет парсить частотности.
Укажите параметры сбора частотности. Инструмент собирает частотности по запросам в широком соответствии, фиксирует количество слов и морфологию, фиксирует порядок слов.
Для запуска задачи нажмите кнопку «Запустить проверку». Время сбора зависит от количества запросов, регионов и типов соответствия.
Отчет доступен в списке задач в формате XLSX.
В отчете указывается частотность запросов в разных типах соответствия. Удалите слова с нулевой и околонулевой частотностью.
Важно! Будьте внимательны с ключевыми словами, связанными с сезонными товарами/услугами. В Вордстате статистика собирается за последний месяц, поэтому если сейчас в вашей нише спад, частотность будет низкой
Детально об анализе частотности в Вордстате мы писали здесь. Также вам может помочь сервис Google Trends. Как с ним работать, тоже рассказывали.
После удаления «нулевок» можно приступать к группировке слов.
PHP Формы
Особенности сбора семантики по видам проектов
В зависимости от размера сайта, количества оказываемых услуг или продаваемых товаров мы собираем семантику различного размера и затрачиваем на это разное количество времени.
Средний сайт с категориями/подкатегориями, но без товаров
Если категорий на сайте много, то для начала узнаем список наиболее интересных клиенту. Если предпочтений нет, выбираем на своё усмотрение. По ним собираем слова из Яндекс Вордстата и чаще всего сразу поисковые подсказки. Если запросов набирается мало, то расширяем список с помощью дополнительных сервисов.
Работаем с получившимся списком, оптимизируем страницы под подобранные для продвижения ключевые слова.
Затем поэтапно собираем запросы для следующих категорий и т.д.
Если в процессе сбора коммерческой семантики находятся информационные запросы и позволяет время, оставляем их в отдельном списке. Такие ключевые слова часто используются в будущем при написании статей для блогов на сайтах.
Процесс отличается от предыдущего вида проекта тем, что на основе собранной семантики мы смотрим, каких срезов не хватает на сайте, но их спрашивают люди.
Срез — это страница с товарами категории или подкатегории каталога отфильтрованными по определенному параметру. Например по цвету, бренду, размеру и т.д.
Вспомним пример, который был выше, про категорию красные платья. Найденные в списке запросов для этой категории «короткие красные платья» и подскажут нам, что следует создать соответствующий срез.
Нельзя забывать, что популярными могут быть не только категории продукции, но и конкретные модели товаров. Находя такие запросы в собранном списке, мы обязательно проверяем их наличие в каталоге сайте.
Примечание. При формировании итогового списка запросов обязательно учитываем геозависимость, коммерциализацию и максимальную достижимую позицию. Почитать об этих факторах можно в нашей статье.
Скидка за объем приобретаемого товара
Принцип составления семантического ядра
Общий принцип составления семантического ядра, это подобрать определенное количество ключевых фраз, по которым с одной стороны поисковики будут находить сайт, а посетители будут входить на него и дальше двигаться по сайту за счет навигации и разлиновки (внутренних ссылок) сайта. С другой стороны, эти ключевые фразы должны быть востребованы пользователями, то есть по этим фразам должны в принципе делаться запросы в поисковых системах.
Низкочастотные, среднечастотные и высокочастотные запросы
Запросы, которые пользователи делают в поисковых системах, аккуратно учитываются и сохраняются поисковыми системами. Более того, статистика запросов доступна для пользователей.
Все запросы разделены на три типа: низкочастотные (НЧ), среднечастотные (СЧ) и высокочастотные (ВЧ) запросы.
Для разделения запросов по этим типам можно использовать цифровую характеристику (количество запросов в месяц из статистики поисковиков) или логическую характеристику.
Например:
- ВЧ запрос это запрос пользователя самого общего характера. Предположим «Мебель»;
- СЧ запрос это уточненный запрос – «Мебель для дома», «Мебель для офиса»;
- НЧ запросы это конкретизированный запрос- «Мебель для дома красного цвета», «Мебель для дома красного цвета итальянского производства».
Как видите, НЧ запросы входят в СЧ запросы, а СЧ входят в ВЧ. По количеству, пользователями делается больше всего ВЧ запросов, меньше всего НЧ запросов.
Зачем нужно знать про НЧ, СЧ, ВЧ запросы
Напоминаю, мы составляем семантическое ядро еще не существующего сайта, только по его тематике. Сайт не имеет ни трафика, ни подписчиков, ничего, кроме темы.
Понятное желание включить в семантическое ядро своего сайта только ВЧ запросы, которые ищут тысячи пользователей, не гарантирует, что по этим запросам к вам придут пользователи. Слишком высока конкуренция.
В SEO для запросов есть еще одна характеристика, называемая конкуренция запроса. Разделение аналогичное. По конкуренции запросы делятся на высоко конкурентные (ВК), средне конкурентные (СК) и низко конкурентные запросы (НК). Прямой связи между частотой запросов и их конкурентностью нет. То есть, СЧ запросы могут быть и низкоконкурентным и высококонкурентными.
Кластеризация запросов
Кластеризацией называется распределение ключевых слов по группам, запросы в которых отвечают одной и той же потребности пользователя и должны продвигаться в Яндексе, Гугле и остальных поисковиках на одну страницу сайта.
Чтобы процесс кластеризации не был долгим по времени мы подбираем запросы сразу по группам. При сборе вручную через Yandex Wordstat так происходит по умолчанию. В Кейколлекторе для каждой продвигаемой страницы создаем отдельную группу и запускаем сбор ключевых слов отдельно для каждой группы.
Если после сбора через Key Collector запросы внутри группы всё-таки надо кластеризовать, то создаем новую группу, фильтруем список по слову и отфильтрованные запросы переносим в нее.
Видео: троянский вирус
Что такое ТРОЯН?
Смотреть видео
Нашли в тексте ошибку? Выделите её, нажмите Ctrl + Enter и мы всё исправим!
Статья обновлена: 13.05.2019
Очистка СЯ от «мусора»
Покажем, как это делать в Key Collector.
Ключевики, которые содержат ненужные слова
Нажимаем вкладку выбора условий фильтрации:
Задаем условие, как указано на скриншоте, и пишем слова:
Отмечаем фразы и добавляем в корзину:
Повторы слов
Аналогично вызываем настройки фильтрации фраз и выбираем такой вариант:
Стоп-слова (информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.)
Нажимаем этот значок в верхнем меню:
В окне настроек добавляем фразы (1) и разбиваем по группам (2):
Далее — выделяем слова в таблице галочкой и добавляем в список стоп-слов.
Группы слов
Чтобы разбить запросы на группы, на вкладке «Данные» открываем «Анализ групп». В окне выбираем тип «По отдельным словам»:
Выбранные группы появятся в основном списке запросов, где можно отсеять все ненужные.
Запросы с нулевой частотностью
Выбираем следующее условие фильтрации:
Далее — требования по частоте:
Можно удалить нецелевые запросы и вручную: копируем ключевики в Word. Заменяем пробел на знак абзаца, чтобы представить все слова из словосочетаний в виде колонки. Переносим обратно в Excel на отдельный лист, сортируем и определяем минус-слова. Затем находим с помощью фильтра фразы с ними и удаляем.
На какие вопросы машинный интеллект не дает ответы
Сбор семантики быстрее и проще с помощью различных сервисов, баз, приложений — благо, выбор есть. Однако нельзя слепо полагаться на автоматизацию. Есть два случая, когда без ручного труда не обойтись. Уже при подборе масок нужно «вытаскивать» синонимы и переформулировки из сайтов заказчика и конкурентов, правой колонки Wordstat, собственных идей и т.д. Мы увидели, что это всё предстоит делать специалисту по контекстной рекламе. Самый трудозатратный и не автоматизируемый процесс — очистка СЯ от «мусора». Готовых минус-списков и данных об отказах из Яндекс.Метрики недостаточно для 100% точности. Приходится смотреть предварительные списки и выявлять смысловое соответствие результатов бизнесу. Особенно это касается сложных продуктов. Например, подготовка сжатого воздуха, или осушка воздуха. Больше расширений можно насобирать по слову «осушка». Но среди результатов в Wordstat в мы можем увидеть и «осушка газа», и «адсорбционная осушка», и «осушка компрессора». Не всегда семантическое соответствие гарантирует смысловое соответствие. Это разные продукты, а значит, разный спрос. Чаще всего выявить и исключить его можно только вручную. Если вы не проверяете результаты парсинга, вы жертвуете полнотой СЯ и точностью будущих рекламных кампаний. Совет: выбирайте оптимальный баланс «трудозатраты — полнота» и делайте полный список минус-слов.
SEO или контекст – что лучше
Как планировать маркетинг
Предприниматель / директор / коммерсант научился контексту или SEO на курсах. Он впервые узнал об этом и теперь применяет повсюду.
В современных условиях нужно окупаться на любых каналах. Принципиальной идеологической разницы между ними быть не должно.
Как это выглядит при нормальном планировании? Сначала мы определяемся с нишей, делаем HTML-макет сайта, движок, и тут же начинаем составлять семантику
При этом важно, чтобы структура зависела не от каталога и не от вашего видения разделов, а от семантики. То, что люди ищут чаще всего, разместите на видных местах.
После того, как собрали семантику и определились со структурой, создаем и наполняем контентом сайт.
Рекомендация: сначала контекст, потом SEO
Можно почистить и сгруппировать семантику и запустить контекст, чтобы бизнес зарабатывал деньги. Пусть не очень большие суммы (200-400 тысяч рублей), но быстро. За 2-4 месяца можно построить цепочку продаж, чтобы реинвестировать эти деньги под SEO.
В чем синергия процессов? Результаты, полученные при кластеризации в контексте, можно использовать при кластеризации в SEO. Не всё и не всегда будет одинаково, но многое можно взять из контекста для SEO.
Вывод: SEO и контекст скоро станут почти неразличимы, а экономия от их синергии растет.
Подбор посадочных страниц
После группировки запросов необходимо распределить их по страницам сайта. Стоит отметить, что слова из одного кластера должны вести на одну страницу. При этом на одну и ту же страницу могут вести несколько кластеров одновременно (например, кластеры «магазин офисной мебели», «недорогая офисная мебель», «купить мебель для офиса» могут вести на главную страницу).
Как же правильно группировать запросы? Вот три основных принципа:
- на главную страницу должны вести брендовые запросы и те, которые максимально обобщённо раскрывают тематику сайта и направление бизнеса;
- на страницы-рубрики переходы обеспечивают конверсионные запросы;
- на статьи, посты и информацию о товаре/услуге, как правило, ведут информационные и низкочастотные запросы с дополнительными словами.
Вот и всё. В результате у вас будет таблица Excel, в которой собраны запросы для продвижения сайта, а также указаны страницы, на которые они должны вести.
Простое мобильное приложение, информирующее об остатках на складах и ценах по штрихкоду, для 1С: УНФ, Розница, УТ 11
Для различных торговых предприятий(магазинов, супермаркетов, торговых баз и т.п.) крайне необходимо персоналу, быстро уточнять наличие на складе или цену продаваемой номенклатуры. Что может быть проще взять свой смартфон навести камеру, и все выяснить.
Но не тут то было, в стандартном функционале 1С Розницы, УНФ, Торговли и т.п., ничего для быстрой обработки штрихкодов нет. На инфостарте ничего нужного, я также не нашел. В итоге пришлось разработать данное решение.
2 стартмани
Семантика для фидов
Зачем её собирать
Реклама по фидам работает хорошо в соответствующих нишах – книги, автозапчасти, комплектующие для компьютеров, спецтехника, электронные запчасти и т.д. То есть там, где большое количество товаров, каждый содержит артикул или численный / буквенный индекс и направлен на небольшой спрос.
Семантика для фидов обеспечивает достоверный минус-файл и чистоту трафика.
Стандартного списка минус-слов недостаточно. В лучшем случае они закрывают 30-40% реальных минус-слов. В каждой тематике также есть запросы, которые содержат характерные слова и делают сам запрос нецелевым, нерелевантным для вас
Поэтому нужно собирать минус-слова для фидов на основе реальных запросов.
Когда вы рекламируетесь по большому массиву товаров, важно запретить показы по запросам, на которые вы не даете ответа – они снижают CTR и повышают цену. Например, в теме автозапчастей это «как установить своими руками»
Вам, как продавцу, они вообще не нужны.
Пример – запросы по автозапчастям Bosch. Это массив в несколько сотен тысяч. Из него мы выделили те, которые содержат цифры – это запросы товарные, таких получилось 20-30 тысяч. Мы составили из них частотный словарь, чтобы найти группы с нерелевантным спросом. Важно брать реальные фразы по конкретному бренду.
Это дает более точный файл минус-слов, на основе которого можно запретить нецелевые показы. В итоге по России средняя цена клика составила 7-10 рублей, а цена заявки – 60-70 рублей. Мы добились высокой конверсии, так как привлекали только трафик, близкий к покупке.
Подводные камни рекламы на фидах
Это «фэйковые» артикулы и названия товаров.
Допустим, у вас 10 тысяч автозапчастей
В процессе важно проверить, нет ли среди артикулов двойные значения. Он может означать как товар, так и ГОСТ, инструкцию, которые не имеют отношения к вашей тематике
Или товар абсолютно из другой области.
Как это проверить? Берете список артикулов и пробиваете по ним частотность. Также вручную выявляете артикулы с двойным значением. По ним уточняете семантику – добавляете название бренда или уточняющие слова, чтобы исключить показы по нецелевому охвату.
Достаточно ли в объявление добавить артикул или нужно «%артикул + %купить (или другое транзакционное слово)»
Второй вариант не дает дополнительного трафика, но вы можете напрямую контролировать позицию объявления не только по запросу артикула, но и по запросу «%артикул + %купить» через подключение биддера.
Так было до недавнего времени. На очень больших товарных фидах не хватало баллов, чтобы загрузить много ключевых слов, и приходилось от этого отказываться.
Недавно Яндекс объявил о том, что позиции в рекламной выдаче можно персонализировать так же, как в поисковой выдаче. Каждому пользователю можно показать те результаты, по которым он с большей вероятностью кликнет. Яндекс уходит от торгов за позиции к торгам за аудиторию. Чем большая ставка, тем большую долю можно получить.
Вывод: нет смысла размножать семантику по фидам. Достаточно добавить одно самое широкое название артикула или индекс товара.
Что делать со статусом «мало показов»
В первую очередь смотрите не что и как выпало, а изменился ли трафик. Если нет, переживать не стоит. Значит, эти объявления не генерировали трафик.
Если заметно снизился – не плюс-минус 10% погрешность, а больше, – то нужно разбираться: скорее всего, ошибки в кластеризации по кампании, подборе семантики. Хотя, применительно к фидам, такое маловероятно.
5 типичных ошибок при сборе семантического ядра для сайта
- Избегание ключевых фраз с высокой конкурентностью. Это ведь не обязывает вас во что бы то ни стало выводить сайт в ТОР по этому ключу. Вы можете использовать такую поисковую фразу в качестве дополнения в семантическом ядре, в качестве контент-идеи.
- Отказ от применения ключей с низкой частотностью. Вы можете также использовать подобные поисковые запросы в виде контент-идей.
- Создание интернет-страниц под отдельные поисковые запросы. Наверняка вы видели сайты, где для схожих запросов (например, «купить свадебный торт» и «сделать свадебный торт на заказ») есть своя страница. Но пользователь, который вводит эти запросы, на самом деле хочет одного и того же. Нет смысла делать несколько страниц.
- Создавать семантическое ядро сайта исключительно с помощью сервисов. Конечно, сбор ключей в автоматизированном режиме облегчает жизнь. Но их ценность будет минимальной, если вы не проанализируете результат. Ведь только вы понимаете особенности отрасли, уровень конкуренции и знаете всё о мероприятиях вашей компании.
- Чрезмерный фокус на сборе ключей. Если у вас небольшой сайт, то начните со сбора семантики с помощью сервисов Яндекса или Google. Не стоит сразу заниматься анализом семантического ядра на сайтах конкурентов или сбором ключей с разных поисковиков. Все эти способы вам пригодятся тогда, когда вы поймете, что пора расширять ядро.
Задача
Перед подразделением разработки индивидуальных инструментов автоматизации eLama.ru поставили задачу автоматизировать сбор семантики для категории детских товаров интернет-гипермаркета Ozon.ru. При этом нужно было отобрать фразы, которые бы обеспечили выполнение KPI по ROI контекстной рекламы категории.
Специфика тематики
В тематике детских товаров есть несколько особенностей. Во-первых, категория содержит огромное количество наименований товаров (более 70 тысяч товаров). А во-вторых, названия товаров этой категории зачастую довольно специфические. Например, грузовик-погрузчик без приставки «игрушечный» будет нерелевантным
А некоторые характеристики товаров могут, напротив, не иметь значения, например, для товара с названием «игрушка-пылесос с вишенками» совсем не важно, что на нем изображено, поскольку пользователи не ищут игрушечный пылесос именно с вишенками
Генерировать и управлять
Генерация и управление ставками — это процессы, только на первый взгляд несвязанные. Генератор создал кампанию, ее загружают в рекламную систему, а дальше уже система управления ставками (бид-менеджер, оптимизатор конверсии, автоматическая стратегия или любая другая) применяет алгоритмы и корректирует ставки.
Но дело в том, что какие бы алгоритмы не работали, бид-менеджеру нужно набрать достаточно статистики, чтобы строить точные прогнозы. Поэтому чем больше семантики сгенерировано, тем больше придется потратить средств на накопление достоверной статистики. И, соответственно, тем ниже показатели эффективности — CPA, ДРР и чистая прибыль. Особенно актуально это на старте — в процессе обучения системы управления ставками. Такую задачу можно решить сегментацией или кластеризацией низкочастотных фраз по посадочным страницам/типам генерации/вендорам.








