Как извлечь картинки из pdf
Содержание:
- Через Adobe Reader или Foxit Reader
- Извлечение изображений из PDF
- Что такое оптимизация на Андроид
- Вставка текстового содержимого копированием
- Использование функции печати в Проводнике Windows
- 3. Как вставить PDF в Word как объект
- Как вытащить изображение из PDF (3 способ)
- Экспорт в XML
- Как конвертировать pdf в jpg
- SmallPDF
- Как преобразовать PDF в JPG онлайн?
- Создание PDF файла с JPG картинками с помощью Word
- SmallPDF
- Экспорт PDF в JSON
- 4. Как конвертировать PDF в документ Word
- 11 неизвестных, но нужных фишек WhatsApp
- Как в PDF добавить страницу из другого PDF
- Программы для перевода PDF в Word
- Как в PDF разделить страницы на разные файлы
- Выводы статьи
Через Adobe Reader или Foxit Reader
Если у вас старая версия MS Word, но зато есть программа Adobe Acrobat Reader или Foxit Reader (в одной из них обычно и открываются все pdf файлы), тогда конвертировать можно с помощью нее.
1. Открываем файл в Adobe Reader или Foxit Reader и копируем нужный фрагмент документа.
Обычно достаточно просто открыть файл и он сразу же запустится в одной из этих программ (вверху будет написано, в какой именно).
Для копирования всего текста в Adobe Reader нажимаем вверху на «Редактирование» и выбираем «Копировать файл в буфер обмена».
В Foxit Reader для переноса всего текста нужно нажать на «Главная» вверху, щелкнуть по иконке буфера обмена и выбрать «Выделить все». Затем опять щелкнуть по иконке и выбирать «Копировать».
2. Создаем документ в Ворде. Для этого щелкаем на свободном любом месте Рабочего стола правой кнопкой мыши и выбираем пункт Создать → Документ Microsoft Office Word.
А можно просто открыть программу через Пуск → Все программы → Microsoft Office → Microsoft Office Word.
3. Вставляем в документ тот фрагмент, который мы скопировали из pdf файла. Для этого щелкаем правой кнопкой мыши по листу и в контекстном меню выбираем пункт «Вставить».
В итоге получаем тот же текст, но с возможностью редактирования. Правда, часто он добавляется с немного измененным форматированием и без изображений.
Минусы
- Если документ большой, вставка происходит очень медленно или Ворд просто намертво виснет. А, бывает, даже небольшой текст не вставляется. Выход: выделять/копировать/вставлять по частям.
- Не копируются изображения. Выход: делать их скриншоты, нажав на клавишу клавиатуры Print Screen, после чего вставлять в Ворд (правая кнопка – Вставить). Но придется еще обрезать и менять размер полученной картинки.
- Иногда форматирование страдает очень сильно: шрифты, размер букв, цвета и т. д. Выход: править текст вручную.
Резюме: с обычным текстом такой вариант вполне допустим, но если в документе есть еще и таблицы, списки, изображения, лучше конвертировать другими способами.
Извлечение изображений из PDF
К сожалению, не существует пакетов Python, которые выполняют извлечение изображений из PDF. Наиболее близкий проект, который я нашел – это minecart, который может делать это, но он работает только на Python 2.7. У меня не вышло его запустить при работе с примером PDF, который у меня был. Однако есть способ, который позволяет извлекать JPG из PDF. Вот пример кода:
Python
# Извлечение jpg из pdf. Быстро и дерзко:
import sys
pdf = file(sys.argv, «rb»).read()
startmark = «\xff\xd8»
startfix = 0
endmark = «\xff\xd9»
endfix = 2
i = 0
njpg = 0
while True:
istream = pdf.find(«stream», i)
if istream < 0:
break
istart = pdf.find(startmark, istream, istream+20)
if istart < 0:
i = istream+20
continue
iend = pdf.find(«endstream», istart)
if iend < 0:
raise Exception(«Didn’t find end of stream!»)
iend = pdf.find(endmark, iend-20)
if iend < 0:
raise Exception(«Didn’t find end of JPG!»)
istart += startfix
iend += endfix
print(«JPG %d from %d to %d» % (njpg, istart, iend))
jpg = pdf
jpgfile = file(«jpg%d.jpg» % njpg, «wb»)
jpgfile.write(jpg)
jpgfile.close()
njpg += 1
i = iend
|
1 |
# Извлечение jpg из pdf. Быстро и дерзко: importsys pdf=file(sys.argv1,»rb»).read() startmark=»\xff\xd8″ startfix= endmark=»\xff\xd9″ endfix=2 i= njpg= whileTrue istream=pdf.find(«stream»,i) ifistream< break istart=pdf.find(startmark,istream,istream+20) ifistart< i=istream+20 continue iend=pdf.find(«endstream»,istart) ifiend< raiseException(«Didn’t find end of stream!») iend=pdf.find(endmark,iend-20) ifiend< raiseException(«Didn’t find end of JPG!») istart+=startfix iend+=endfix print(«JPG %d from %d to %d»%(njpg,istart,iend)) jpg=pdfistartiend jpgfile=file(«jpg%d.jpg»%njpg,»wb») jpgfile.write(jpg) jpgfile.close() njpg+=1 i=iend |
Это также работает для тех файлов PDF, которые я использую. В StackOverflow есть вариации этого кода, некоторые из которых используют PyPDF2 различными способами. Однако в моем случае они не помогли.
Я рекомендую использовать инструмент Poppler для извлечения изображений. Poppler включает в себя инструмент под названием pdfimages, который вы можете использовать с модулем Python под названием subprocess. Вот как использовать его без Python:
Shell
pdfimages -all reportlab-sample.pdf images/prefix-jpg
| 1 | pdfimages-all reportlab-sample.pdfimagesprefix-jpg |
Убедитесь в том, что папка с изображениями (или папку любой другой выдачи, которую вы хотите создать) уже создана, так как pdfimages не сделает это за вас.
Давайте напишем скрипт Python, который выполняет эту команду, и убедимся, что папка выдачи также существует:
image_exporter.py
Python
# image_exporter.py
import os
import subprocess
def image_exporter(pdf_path, output_dir):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
cmd = [‘pdfimages’, ‘-all’, pdf_path,
‘{}/prefix’.format(output_dir)]
subprocess.call(cmd)
print(‘Images extracted:’)
print(os.listdir(output_dir))
if __name__ == ‘__main__’:
pdf_path = ‘reportlab-sample.pdf’
image_exporter(pdf_path, output_dir=’images’)
|
1 |
# image_exporter.py importos importsubprocess defimage_exporter(pdf_path,output_dir) ifnotos.path.exists(output_dir) os.makedirs(output_dir) cmd=’pdfimages’,’-all’,pdf_path, ‘{}/prefix’.format(output_dir) subprocess.call(cmd) print(‘Images extracted:’) print(os.listdir(output_dir)) if__name__==’__main__’ pdf_path=’reportlab-sample.pdf’ image_exporter(pdf_path,output_dir=’images’) |
В этом примере мы импортировали модули subprocess и os. Если папка выдачи не существует, мы попытаемся создать её. Далее мы используем метод вызова subprocess для запуска pdfimages. Мы используем вызов, так как он будет ожидать pdfimages, пока тот закончит работу. Вы можете использовать Popen вместо этого, но это фактически запускает процесс в фоновом режиме. Наконец, мы выводим список папки выдачи для подтверждения того, что изображения были добавлены в неё.
Есть статьи, которые ссылаются на библиотеку под названием Wand, которую вы тоже можете попробовать. Это оболочка ImageMagick
Также обратите внимание на то, что существует связка Python с Poppler под названием pypoppler, однако я не нашел примеров того, что этот пакет выполняет извлечение изображений
Что такое оптимизация на Андроид
Вставка текстового содержимого копированием
Здесь необходимо любым известным вам способом скопировать текст из пдф файла и вставить его в документ Word. Можно скопировать фрагмент или все сразу (CTRL+A). При вставке содержимого выбирайте команду Сохранить исходное форматирование
.
Это простые способы вставки содержимого пдф, которые требуют некоторого усилия для приведения текста в нормальный вид. Но в интернете вы можете найти сервисы по преобразованию pdf в Word. Но они не всегда дают ожидаемый результат, и правка форматирования возможно у вас отнимет не меньше времени, чем описанный выше способ. Или же установить на компьютер специальную программу распознавания, которую еще нужно будет освоить. Ну, если вам не срочно, то можно и так. Пробуйте и решайте, что удобнее для вас.
Решение проблемы
Если вы обладатель , то при открытии документ PDF в них будет автоматически преобразован в редактируемый формат. Ставьте последние версии Word.
Использование функции печати в Проводнике Windows
В Проводнике Windows можно использовать функцию печати для известных операционной системе графических файлов.
Использовать Проводник для сохранения фотографий в PDF очень просто:
- Откройте любую папку на компьютере, в которой находятся изображения, например, Рабочий стол. Выделите одну или несколько фотографий.
- После клика правой кнопкой мыши по фотографии, картинке или изображению, в контекстном меню Проводника появится пункт «Печать», на который нужно нажать.
- В окне «Печать изображений» выберите виртуальный принтер, другие параметры печати.
- Нажмите на кнопку «Печать».
В открывшемся окне выберите название для файла, место для сохранения, нажмите «Сохранить».
3. Как вставить PDF в Word как объект
Вы можете вставить свой PDF в Word как объект. Это означает, что вы можете легко получить доступ к PDF из вашего документа Word. Кроме того, в зависимости от выбранных параметров PDF-файл может обновляться автоматически.
Для этого откройте Word и перейдите на вкладку « Вставка » на ленте. В разделе « Текст » нажмите « Объект» .
В открывшемся окне перейдите на вкладку « Создать из файла ». Нажмите Обзор … , найдите и выберите свой PDF, затем нажмите Вставить .
На данный момент, вы можете просто нажать кнопку ОК . Это вставит статический захват первой страницы PDF в документ Word. Если дважды щелкнуть этот скан, откроется PDF-файл.
Кроме того, вы можете выбрать ссылку на файл . Хотя при этом по-прежнему вставляется только первая страница PDF, любые изменения, которые происходят в этом PDF, будут автоматически отражаться в документе Word.
Если вы не хотите видеть первую страницу, выберите View as Icon . По умолчанию будет отображаться значок Adobe PDF и название вашего PDF. Вы можете нажать Изменить значок …, если вы хотите отобразить другой значок.
Как вытащить изображение из PDF (3 способ)
В некоторых случаях, у пользователей возникают затруднения, когда они пытаются вытащить картинку из PDF первыми двумя способами, а ничего не получается.
Файл в формате PDF может быть защищен. Поэтому, извлечь картинки из PDF файла такими способами не удается.
В некоторых ситуациях, необходимо скопировать картинку из PDF, которая не имеет четких прямоугольных границ. Давайте усложним задачу. Как быть, если из защищенного PDF файла нужно скопировать изображение, не имеющее четких границ (обрамленное текстом или другими элементами дизайна)?
Можно очень легко обойти эти препятствия. Решение очень простое: необходимо воспользоваться программой для создания снимков экрана. Потребуется всего лишь сделать скриншот (снимок экрана) необходимой области, которую входит интересующее нас изображение.
Откройте PDF файл в программе Adobe Acrobat Reader. Затем запустите программу для создания скриншотов. Для этого подойдет стандартная программа «Ножницы», входящая в состав операционной системы Windows, или другая подобная более продвинутая программа.
Я открыл в Adobe Reader электронную книгу в формате PDF, которая имеет защиту. Я хочу скопировать изображение, которое не имеет четких прямоугольных границ.
Для создания снимка экрана, я использую бесплатную программу PicPick (можно использовать встроенное в Windows приложение Ножницы). В программе для создания скриншотов, нужно выбрать настройку «Захват произвольной области».
Далее с помощью курсора мыши аккуратно обведите нужную картинку в окне программы, в данном случае, Adobe Acrobat Reader.
Вам также может быть интересно:
- Как сохранить картинки из Word
- Как сохранить файл в PDF — 3 способа
После захвата изображения произвольной области, картинка откроется в окне программы для создания скриншотов. Теперь изображение можно сохранить в необходимый графический формат на компьютере. В настройках приложения выберите сохранение картинки в соответствующем формате.
Экспорт в XML
Формат eXtensible Markup Language (XML) – это один из самых известных форматов ввода и вывода. Он широко используется в интернете для различных целей. Как мы уже видели в этой статье, PDFMiner также поддерживает XML в качестве одного из вариантов выдачи.
Давайте создадим наш инструмент создания XML. Простой пример:
xml_exporter.py
Python
# xml_exporter.py
import os
import xml.etree.ElementTree as xml
from miner_text_generator import extract_text_by_page
from xml.dom import minidom
def export_as_xml(pdf_path, xml_path):
filename = os.path.splitext(os.path.basename(pdf_path))
root = xml.Element(‘{filename}’.format(filename=filename))
pages = xml.Element(‘Pages’)
root.append(pages)
counter = 1
for page in extract_text_by_page(pdf_path):
text = xml.SubElement(pages, ‘Page_{}’.format(counter))
text.text = page
counter += 1
tree = xml.ElementTree(root)
xml_string = xml.tostring(root, ‘utf-8′)
parsed_string = minidom.parseString(xml_string)
pretty_string = parsed_string.toprettyxml(indent=’ ‘)
with open(xml_path, ‘w’) as fh:
fh.write(pretty_string)
#tree.write(xml_path)
if __name__ == ‘__main__’:
pdf_path = ‘w9.pdf’
xml_path = ‘w9.xml’
export_as_xml(pdf_path, xml_path)
|
1 |
# xml_exporter.py importos importxml.etree.ElementTreeasxml fromminer_text_generator importextract_text_by_page fromxml.domimportminidom defexport_as_xml(pdf_path,xml_path) filename=os.path.splitext(os.path.basename(pdf_path)) root=xml.Element(‘{filename}’.format(filename=filename)) pages=xml.Element(‘Pages’) root.append(pages) counter=1 forpage inextract_text_by_page(pdf_path) text=xml.SubElement(pages,’Page_{}’.format(counter)) text.text=page100 counter+=1 tree=xml.ElementTree(root) xml_string=xml.tostring(root,’utf-8′) parsed_string=minidom.parseString(xml_string) pretty_string=parsed_string.toprettyxml(indent=’ ‘) withopen(xml_path,’w’)asfh fh.write(pretty_string) #tree.write(xml_path) if__name__==’__main__’ pdf_path=’w9.pdf’ xml_path=’w9.xml’ export_as_xml(pdf_path,xml_path) |
Этот скрипт будет использовать встроенные библиотеки XML: minidom и ElementTree. Мы также импортируем скрипт генератора PDFMiner, который мы используем для того, чтобы выделять текст постранично. В данном примере, мы создадим элемент высшего уровня, который является названием файла PDF. Далее, мы добавляем элемент Pages под ним. После этого, переходим к циклу for, где мы извлекаем каждую страницу PDF и сохраняем информацию, которая нам нужна. Здесь вы можете добавить специальный парсер, в котором вы можете разделить страницу на предложения или слова и парсить более интересную информацию. Например, вам могут понадобиться предложения с определенным именем, данными, указанным временем. Вы можете использовать регулярные выражения Python для поиска, или проверить наличие наследуемых строк в предложении.
Для этого примера мы просто извлечем 100 символов из каждой страницы и сохраним их в SubElement XML. Технически, следующая часть кода может быть упрощена, чтобы просто вписать XML. Однако, ElementTree ничего не делает с XML, чтобы сделать его читабельным. Это больше похоже на минимизированный javascript: просто большой блок текста.
Так что вместо того, чтобы вписывать этот блок текста в диск, мы используем minidom, чтобы облагородить XML пробелами, перед тем как сохранять. Результат должен выглядеть следующим образом:
|
1 |
<?xml version=»1.0″?> <w9> <Pages> <Page_1>Form W-9(Rev. November 2017)Department of the Treasury Internal Revenue Service Request for Taxp</Page_1> <Page_2>Form W-9 (Rev. 11-2017)Page 2 By signing the filled-out form, you: 1. Certify that the TIN you are g</Page_2> <Page_3>Form W-9 (Rev. 11-2017)Page 3 Criminal penalty for falsifying information. Willfully falsifying cert</Page_3> <Page_4>Form W-9 (Rev. 11-2017)Page 4 The following chart shows types of payments that may be exempt from ba</Page_4> <Page_5>Form W-9 (Rev. 11-2017)Page 5 1. Interest, dividend, and barter exchange accounts opened before 1984</Page_5> <Page_6>Form W-9 (Rev. 11-2017)Page 6 The IRS does not initiate contacts with taxpayers via emails. Also, th</Page_6> </Pages> </w9> |
Это делает XML чище и более читабельным. В качестве бонуса, вы также можете воспользоваться методом извлечения метадаты из PDF и добавить её в свой PDF при помощи PyPDF2.
Как конвертировать pdf в jpg
Есть много способов, чтобы переформатировать pdf в jpg, но не все из них выгодны и удобны. Некоторые и вовсе абсурдные, что о них даже слышать никому не стоит. Рассмотрим два самых популярных способа, которые помогут сделать из файла pdf набор изображений в формате jpg.
Способ 1: использование онлайн конвертера
- После того, как сайт загрузился, можно добавлять в систему нужный нам файл. Сделать это можно двумя способами: нажать на кнопку «Выбрать файл» или перенести сам документ в окно браузера в соответствующую область.
Перед конвертацией можно изменить некоторые настройки, чтобы полученные в итоге документы jpg были качественными и читаемыми. Для этого пользователю представлена возможность изменить цвета графических документов, разрешение и формат изображений.
После загрузки документа pdf на сайт и настройки всех параметров можно нажимать на кнопку «Конвертировать». Процесс займет некоторое время, поэтому придется немного подождать.
Как только процесс конвертации завершится система сама откроет окно, в котором необходимо будет выбрать место для сохранения полученных файлов jpg (сохраняются они в одном архиве). Теперь осталось только нажать на кнопку «Сохранить» и пользоваться изображениями, полученными из документа pdf.
Способ 2: использование конвертера для документов на компьютере
- Как только программа установлена на компьютер, можно приступать к конвертации. Для этого надо открыть документ, который необходимо преобразовать из формата pdf в jpg. Рекомендуется работать с документами pdf через программу Adobe Reader DC.
- Теперь следует нажать на кнопку «Файл» и выбрать пункт «Печать…».
Следующим шагом надо выбрать виртуальный принтер, который будет использоваться для печати, так как нам не надо непосредственно распечатать сам файл, надо лишь получить его в другом формате. Виртуальный принтер должен называться «Universal Document Converter».
Выбрав принтер, необходимо нажать на пункт меню «Свойства» и убедиться, что сохраняться документ будет в формате jpg (jpeg). Кроме этого можно настроить много разных параметров, которые невозможно было изменить в онлайн-конвертере. После всех изменений можно нажимать на кнопку «Ок».
Нажатием на кнопку «Печать» пользователь начнет процесс преобразования документа pdf в изображения. После его завершения появится окно, в котором опять придется выбрать место сохранения, название полученного файла.
Вот такие два хороших способа являются наиболее удобными и надежными в работе с pdf файлами. Перевести данными вариантами документ из одного формата в другой довольно просто и быстро. Выбирать какой из них лучше следует только пользователю, ведь у кого-то могут возникнуть проблемы с подключением к сайту загрузки конвертера для компьютера, а у кого-то могут появиться и другие проблемы.
Если вы знаете какие-то еще способы конвертирования, которые будут простыми и не затратными по времени, то пишите их в комментарии, чтобы и мы узнали, о вашем интересном решении такой задачи как конвертирование документа pdf в jpg формат.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
SmallPDF
Этот сервис предлагает конвертировать изображения в JPG формат. Для этого достаточно перетянуть файл в соответствующий прямоугольник или воспользоваться кнопкой ниже для выбора файла.
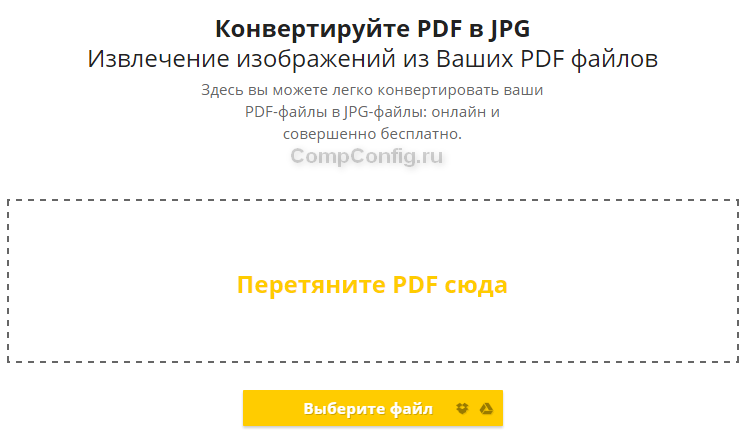
После добавления файла вам будет предложено извлечь отдельные изображения или конвертировать страницы полностью.

Нажимаем «Извлечь отдельные». После окончания этого процесса на экране появятся иконки с извлеченными изображениями, которые можно скачать в архиве ZIP.
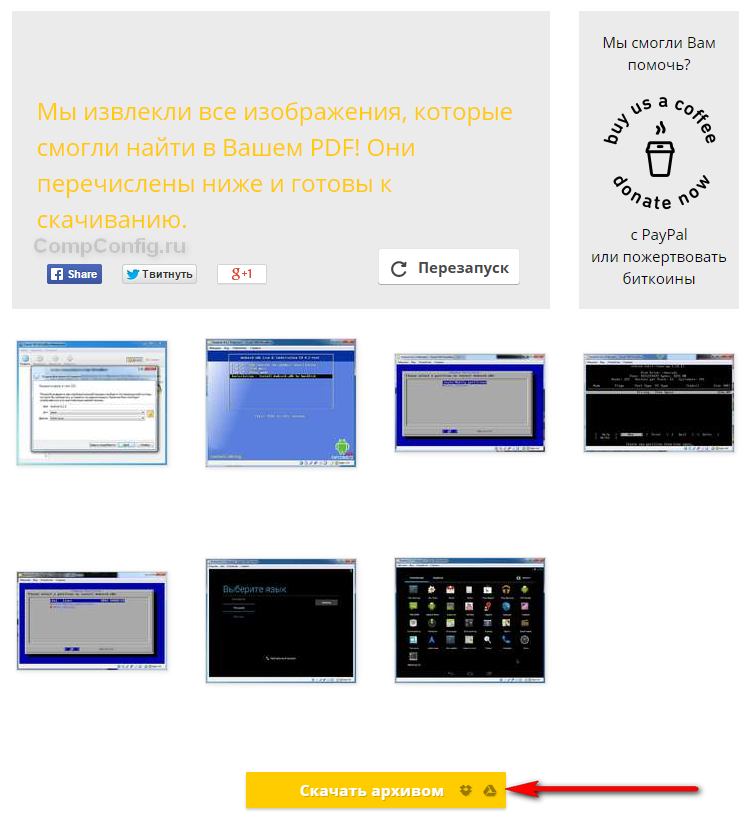
Сервис работает достаточно быстро и отличается оригинальным интерфейсом. Также плюсом является наличие русскоязычной версии.
Как преобразовать PDF в JPG онлайн?
Рассмотрим доступные варианты.
PDF2JPG
Англоязычный бесплатный онлайн-сервис PDF2JPG отличается простотой интерфейса и большой скоростью преобразования файлов. Также к преимуществам утилиты стоит отнести:
- возможность скачать отдельные страницы документа;
- высокое качество конвертированных изображений;
- размер загружаемых файлов ПДФ — до 25 мегабайт, количество страниц при этом неограниченно;
- e-mail уведомления о завершении переформатирования.
Чтобы перевести PDF в JPG, необходимо:
- Указать желаемое качество JPG:
- Average — для документов без иллюстраций;
- Good (по умолчанию) — для PDF с чертежами и схемами;
- Excellent — для файлов с иллюстрациями высокого разрешения.
Нажать «Convert PDF to JPG».
В новой вкладке будут доступны для сохранения на ПК и просмотра в браузере отдельные страницы в переделанном формате, а также архив для скачивания со всеми JPEG-файлами (кнопка «download your pictures as a ZIP file»).
PDFtoImage
PDFtoImage — бесплатный сервис для перевода ПДФ в JPG на русском языке. Его главные отличия от англоязычного аналога: отсутствует функция скачивания отдельных страниц, зато можно одновременно преобразовывать несколько документов.
Чтобы переделать формат PDF в JPG, нужно:
Открыть страницу pdftoimage.com. Нажать на кнопку «Загрузить» для выбора файлов на компьютере либо перетащить их из папки на своем ПК в специальное окно на сайте.
Когда сервис завершит преобразование, можно будет сохранить документы по отдельности либо общим архивом (кнопка «Скачать все»).
Создание PDF файла с JPG картинками с помощью Word
Это может показаться странным, но один из самых простых и надежных способов создать PDF файл из нескольких JPG картинок, это программа Microsoft Word. Также для данной цели подойдут и другие текстовые редакторы похожие на Word. Главное, чтобы они позволяли вставлять в текст картинки и распечатывать документ.
Итак, для того чтобы создать PDF файл из нескольких JPG картинок вам нужно сначала вставить эти картинки в редактор Word. Это можно сделать, просто перетащив картинки в документ либо воспользовавшись кнопкой «Рисунки» на вкладке «Вставка».
После этого нужно разместить JPG картинки на страницах документа Word таким образом, каким они должны размещаться в финальном PDF файле. Если вы хотите, что картинки занимали все пространство листа, то нужно уменьшить поля. Это можно сделать при помощи линейки в верхней и левой части окна.
Если это необходимо, то уменьшая поля и растягивая картинки, можно добиться того, чтобы они вплотную прилегали к краям листа.
После того как все JPG картинки правильно размещены, можно приступать к созданию PDF файла. Для этого откройте меню «Файл – Экспорт» и воспользуйтесь опцией «Создать документ «PDF/XPS».
После этого откроется окно публикации PDF файла. Здесь нужно указать имя файла, выбрать формат, уровень оптимизации (сжатия) и нажать на кнопку «Опубликовать». В результате вы получите PDF файл, который является точной копией созданного вами документа Word.
Если у вас старая версия Word, в которой нет функции экспорта в PDF-формат, то вы можете воспользоваться PDF-принтером. Это специальная программа, которая эмулирует работу принтера, но вместо печати документа сохраняет его в формате PDF. Сейчас существует множество таких программ, вот некоторые бесплатные варианты:
После установки любой из этих программ в списке принтеров появится виртуальный принтер, способный «печатать» в PDF-файл. Теперь, для того чтобы получить PDF файл из документа Word достаточно открыть меню «Файл – Печать», выбрать виртуальный PDD-принтер и запустить печать документа.
После запуска печати откроется окно, которое предложит пользователю сохранить получившийся PDF-документ. Таким образом можно очень просто и быстро создать PDF файл из нескольких JPG картинок с использованием минимума программного обеспечения.
SmallPDF
Веб-сервис SmallPDF, понравился мне больше, чем предыдущий. Та же самая схема была обработана примерно в 2 раза быстрее и загрузилась обратно в считанные секунды. Структура документа, как и в первом случае, сохранилась неизменной, но искажений в нем стало меньше.
Перейти на Smallpdf
Пользоваться SmallPDF тоже очень просто:
- Загружаем или перетаскиваем на выделенное поле ПДФ-файл. Кстати, сервис поддерживает загрузку документов из Dropbox и Google Drive.
- Нажимаем «Конвертировать».
- Скачиваем результат на компьютер либо сохраняем его в своем Dropbox или Google Drive.
Из недостатков SmallPDF стоит отметить лишь два. Первый – это ограничение бесплатной версии двумя загрузками в час (безлимитное использование по подписке стоит $4-6 в месяц). Второй – сохранение результата только в формате DOCX.
Экспорт PDF в JSON
JavaScript Object Notation, или JSON, представляет собой простой формат обмены данными, который легко читать и писать. Python содержит модуль json в своей стандартной библиотеки, который позволяет вам программно читать и писать в JSON. Давайте посмотрим, что мы усвоили из предыдущего раздела и используем это для создания скрипта экспорта, который выдает JSON вместо XML:
json_exporter.py
Python
# json_exporter.py
import json
import os
from miner_text_generator import extract_text_by_page
def export_as_json(pdf_path, json_path):
filename = os.path.splitext(os.path.basename(pdf_path))
data = {‘Filename’: filename}
data = []
counter = 1
for page in extract_text_by_page(pdf_path):
text = page
page = {‘Page_{}’.format(counter): text}
data.append(page)
counter += 1
with open(json_path, ‘w’) as fh:
json.dump(data, fh)
if __name__ == ‘__main__’:
pdf_path = ‘w9.pdf’
json_path = ‘w9.json’
export_as_json(pdf_path, json_path)
|
1 |
# json_exporter.py importjson importos fromminer_text_generator importextract_text_by_page defexport_as_json(pdf_path,json_path) filename=os.path.splitext(os.path.basename(pdf_path)) data={‘Filename’filename} data’Pages’= counter=1 forpage inextract_text_by_page(pdf_path) text=page100 page={‘Page_{}’.format(counter)text} data’Pages’.append(page) counter+=1 withopen(json_path,’w’)asfh json.dump(data,fh) if__name__==’__main__’ pdf_path=’w9.pdf’ json_path=’w9.json’ export_as_json(pdf_path,json_path) |
Здесь мы импортируем различные библиотеки, которые нам могут понадобиться, включая модуль PDFMiner. Далее, мы создаем функцию, которая принимает путь ввода PDF и путь выдачи JSON. JSON – это, фактически, словарь в Python, так что мы создаем несколько простых ключей высшего уровня: Filename и Pages. Ключ Pages сопоставляется с пустым списком. Далее, мы вводим цикл над каждой страницей PDF и извлекаем первые 100 символов каждой страницы. Далее, мы создаем словарь с номером страницы в качестве ключа и 100 символов в качестве значение и добавим в список верхнего уровня Page. Наконец, мы записываем файл при помощи команды модуля json под названием dump.
Содержимое файла должно выглядеть следующим образом:
|
1 |
{‘Filename»w9’, ‘Pages'{‘Page_1»Form W-9(Rev. November 2017)Department of the Treasury Internal Revenue Service Request for Taxp’}, {‘Page_2»Form W-9 (Rev. 11-2017)Page 2 By signing the filled-out form, you: 1. Certify that the TIN you are g’}, {‘Page_3»Form W-9 (Rev. 11-2017)Page 3 Criminal penalty for falsifying information. Willfully falsifying cert’}, {‘Page_4»Form W-9 (Rev. 11-2017)Page 4 The following chart shows types of payments that may be exempt from ba’}, {‘Page_5»Form W-9 (Rev. 11-2017)Page 5 1. Interest, dividend, and barter exchange accounts opened before 1984’}, {‘Page_6»Form W-9 (Rev. 11-2017)Page 6 The IRS does not initiate contacts with taxpayers via emails. Also, th’}} |
И снова мы получили отличную выдачу, которую легко читать. Вы можете улучшить этот пример с метадатой PDF в том числе, если захотите
Обратите внимание на то, что выдача меняется в зависимости от того, что вам нужно пропарсить в каждой странице или документе
Давайте посмотрим, как мы можем проводить экспорт в CSV.
4. Как конвертировать PDF в документ Word
Если вы хотите преобразовать весь PDF в документ Word, вы можете сделать это из самого Word.
В Word перейдите в « Файл»> «Открыть» и выберите PDF. Появится сообщение, предупреждающее о том, что, хотя полученный документ Word будет оптимизирован для редактирования текста, он может выглядеть не совсем так, как исходный PDF. Нажмите OK, чтобы продолжить.
Процесс может занять некоторое время, если это большой PDF, так что наберитесь терпения. После завершения вы можете использовать документ Word, как и любой другой.
Если это не дает желаемых результатов, попробуйте эти другие способы бесплатно конвертировать PDF в Word .
11 неизвестных, но нужных фишек WhatsApp
Как в PDF добавить страницу из другого PDF
С помощью данной опции возможно объединить файлы любого формата, включая Word, Excel, PowerPoint:
В «Инструментах» выбрать пункт «Объединить…».
Перетащить файл прямо в интерфейс программы.
Документы отобразятся на экране.
Если нужно отсортировать страницы, двойным щелчком левой кнопки мышки развернуть документ и путем перетаскивания поменять местами листы.
Для удаления конкретной страницы следует навести на нее курсор и нажать на появившийся значок корзины справа.
После внесенных изменений двойным кликом по первому листу выйти из режима просмотра. Нажать на кнопку «Объединить». Запустится процесс преобразования, который займет несколько секунд (в зависимости от объема).
Для добавления страницы необходимо провести некоторые манипуляции:
- Открыть файл, из которого должен быть изъят один лист.
- Двойным щелчком открыть левую вертикальную панель инструментов.
- Выбрать миниатюры – первый значок.
Вызвать параметры, кликнув на соответствующий значок (расположен возле корзины).
Выбрать опцию «Извлечь…». Указать номер листа, который следует извлечь. Отметить галочкой пункт об изъятии в отдельный файл. Нажать «Ок».
- Закрыть данный файл.
- Открыть документ, в который будет добавлен один лист. Повторить действия из п.2-4.
- Перейти по пути «Вставить страницы» – «Из файла».
- В открывшейся папке выбрать файл.
- Задать настройки, куда будет вставлен новый лист.
Опция доступна только в платной версии программы Acrobat Pro DC.
Программы для перевода PDF в Word
По разным причинам, кому-то может быть неудобно, конвертировать файлы в онлайне, так что рассмотрим на примере программ. Мы рассмотрим конвертацию с помощью программы First PDF. Программа платная, но у нее есть возможность использовать её бесплатно 30 дней или в течении 100 конвертаций.
Если Вам нужно перевести в Word несколько документов сразу, и Вы не планируйте этим заниматься каждый день – то такой вариант отлично подойдет для Вас. Скачиваем программу с официального сайта pdftoword.ru Устанавливаем программу, как и другие: соглашаемся с лицензионным соглашением и нажимаем «Далее». После установки программы будет стоять галочка, которая сразу запустит программу после установки.
При первом запуске программы Вам предложить купить лицензию или пользоваться бесплатной версией, мы выбираем вариант «Продолжить» бесплатно. Перед нами выходит такое окно.
Теперь необходимо нажать на кнопку «Добавить PDF» и выбрать необходимый файл. В настройках программы (справа) Вы можете выбрать путь сохранения файл и открывать ли его сразу после конвертации. Так же можно выбрать страницы, которые необходимо конвертировать, например с «1-3» или оставить все.
Если Вы все выбрали – нажимаем на кнопку «конвертировать» и перед нами снова выходит окно с лицензией. Нажимаем кнопку «Продолжить» (не покупая программу) и файл перейдет в формат Word. Мне очень понравилась данная программа, она быстро и хорошо работает.
Если Вам не достаточно демо-версии программы, и Вы постоянно конвертируйте файлы – приобретите полную версию на сайте разработчиков на 990 рублей (цена актуальна на момент написания данной записи).
Как в PDF разделить страницы на разные файлы
Сделать это проще всего посредством опции систематизации:
Открыть документ, который нужно разделить. Перейти в «Инструменты» – «Систематизировать…».
- На экране отобразятся миниатюры.
- Чтобы сохранить один лист как отдельный файл, для вызова меню нажать «Извлечь», далее отметить галочкой соответствующий пункт и повторно нажать на кнопку «Извлечь».
- Указать путь, куда он должен быть сохранен.
- Если необходимо извлечь все листы документа как несколько отдельных файлов, кликнуть по «Разделить» для вызова меню.
- Вписать количество листов для разделения. В «Параметрах ввода» выбрать папку для сохранения.
Нажать на кнопку «Разделение» или «Разделить на несколько файлов» – результат будет одинаковый.
Опция доступна только в платной версии программы Acrobat Pro DC.
Выводы статьи
С помощью трех простых способов можно легко извлечь картинки из PDF файла. Картинки будут вытащены из PDF, даже в том случае, если на файле PDF стоит защита, или нужное изображение на странице документа PDF не имеет четких прямоугольных границ.
Инструкция
Откройте документ с помощью той программы, которой вы обычно пользуетесь. Наиболее популярная — Adobe Acrobat. В ней предусмотрена функция копирования, и вполне возможно, что больше никаких программ вам и не потребуется. Той же функцией располагает и бесплатная программа FoxReader.
Найдите в главном меню вкладку «Редактирование», а в ней — функции выделения и копирования. Выделить и скопировать нужный фрагмент можно и с помощью правой клавиши мыши.
Последние версии Adobe Acrobat.позволяют сохранить документ как текст. Сохраните, найдите нужный фрагмент и скопируйте. К сожалению, формат txt не позволяет использовать диакритику, поэтому для работы с документами на языках, где много диакритических знаков, этот способ не годится. Не сработает он и в случае, когда текст был картинкой.
Если вас постигла , попробуйте другие программы. Например, откройте документ через текстовый редактор Open Office. Эта программа справляется с форматом pdf довольно успешно, если опять же страница не представляет собой единого изображения.
Попробуйте Abbyy FineReader. Лучше, если у вас стоит одна из последних версий. Откройте файл как изображение и предложите программе его распознать. В главном меню найдите вкладку «Изображение», а в ней — функцию «Тип блока». Выберите то, что вам нужно. Не забудьте выставить язык. При сохранении выберите «Копировать в буфер».
Иной раз Abbyy FineReader распознает подобные файлы неуверенно, а то и вообще может выдать табличку «Увеличьте разрешение сканирования». В этом случае, если документ небольшой, лучше всего сделать скриншот с . Только не забудьте выставить максимальное разрешение. Сохраните картинку в удобном для вас формате изображений, а затем загоните ее в Abbyy FineReader, распознайте и скопируйте.
Полезный совет
Очень полезной может оказаться небольшая древняя программка Pdfwordconvertor. Она покажет, каким образом был отсканирован нужный вам фрагмент. Если это сплошная картинка, то она и откроется как картинка, но уже в формате doc.
удалить лист в пдф
Формат электронной документации PDF, разработанный и активно пропагандируемый компанией Adobe, приобретает в наше время все большую популярность. В таком виде делается большинство современных публикаций, выпускаются электронные инструкции к технике, в нем выпускаются книги и хранятся документы в электронных архивах. При этом довольно часто возникает необходимость в переводе текстовой
информации из.pdf в другие форматы.
Вам понадобится
Компьютер с установленной операционной системой Windows, доступ в интернет, программа для работы с файлами формата.pdf Adobe Reader, начальные навыки по работе с компьютером
Инструкция
Скачайте с разработчика (http://get.adobe.com/reader/
) установочный файл Adobe Reader. Запустите его, выберите путь для установки программы и примите условия лицензионного соглашения. Обязательно дождитесь окончания установки.
В открывшемся документе найдите фрагмент документа, который нужно скопировать, и выделите его с помощью левой кнопки мышки. Нажмите сочетание Ctrl+C. Выделенный фрагмент будет помещен обмена Windows. Если в выделенном фрагменте документа находились изображения, они не будут.
Видео по теме